大数据组件
作为数据开发人员,可能已经接受了SQL Boy的自嘲,但了解背后大数据技术的发展历史,形成知识框架,也算是往前了一步。本文就结合自身的经历,梳理下常用大数据常用组件,希望可以在不同的场景选择合适的技术方案。
一点历史
传统的数据库无法处理量级过大或过于复杂的数据,于是出现了大数据三驾马车——Google于2003开始发布的一系列论文:
The Google File System (2003)
MapReduce: Simplified Data Processing on Large Clusters (2004)
Bigtable: A Distributed Storage System for Structured Data (2006)
基于论文,Yahoo建立了开源的Hadoop(HDFS + MapReduce + YARN)项目,奠定了分布式计算系统的基础,Powerset研发了Bigtable的开源版本HBase,进一步壮大了Hadoop生态。与此同时,在线事务处理(OLTP)和在线分析处理(OLAP)系统同步发展,并也开始融合(HTAP),各种项目百花齐放。

数据存储
存储架构
块存储 vs 文件存储 vs 对象存储
文件存储:HDFS
Unix哲学——一切皆文件,但现在数据开发平台已经屏蔽了相应复杂细节,几乎没有机会直接操作hdfs文件。

对象存储:Minio(兼容S3)
随着云原生的进展,对象存储极致的弹性和成本效益体现了出来,已经开启了存算分离的时代。

存储格式
AVRO vs ORC vs Parquet
行存:Avro
可以用于数据的传输格式,减少带宽占用,但实际使用起来还是json格式方便些。
列存:Parquet
对具体的格式研究不多,但现在Parquet已经成为各大数据湖的默认格式了。
表格式(数据湖)
Iceberg vs Hudi vs DeltaLake vs Paimon
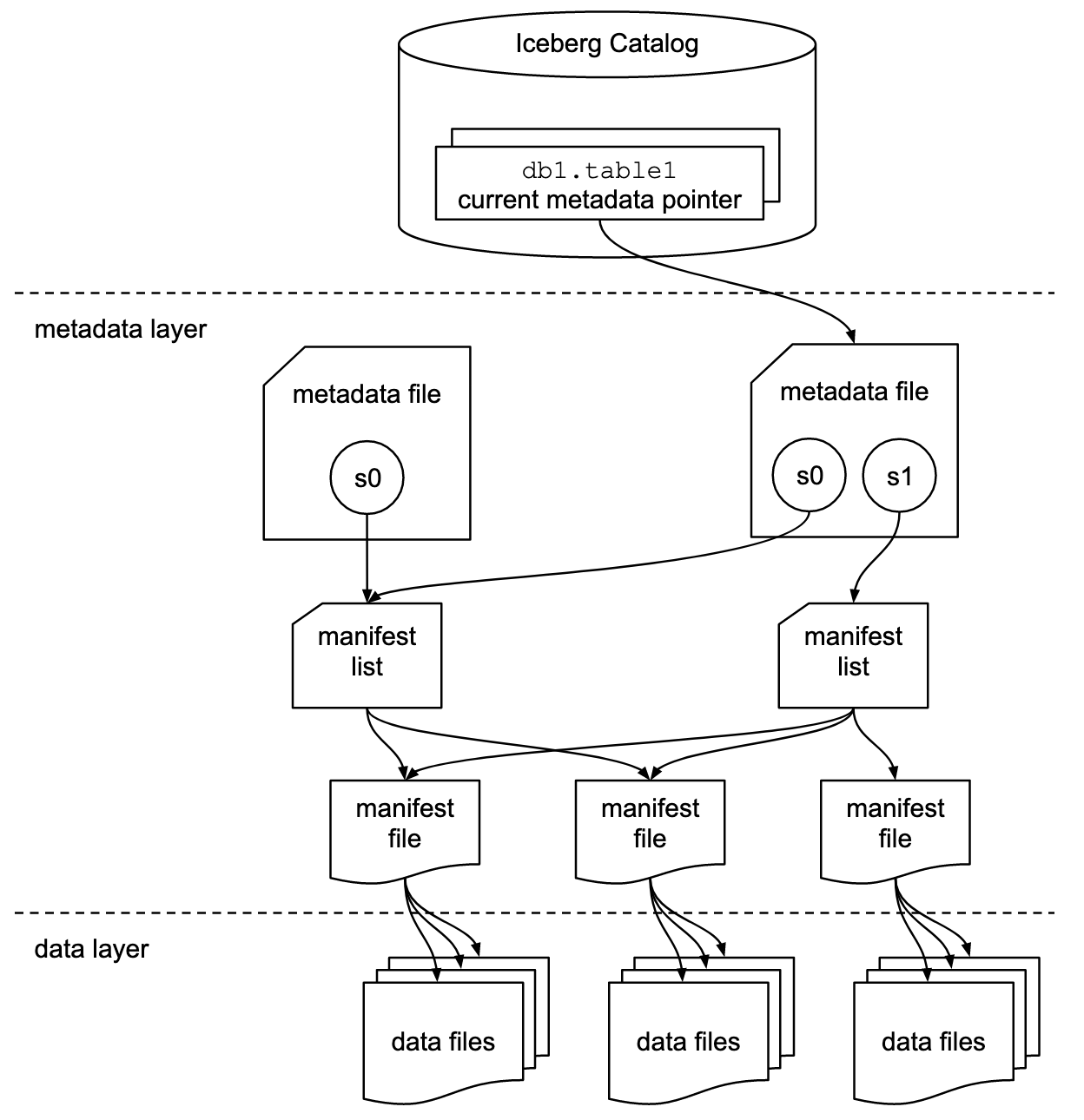
离线分析:Iceberg
Iceberg已经成为表格式的事实标准,成为湖仓一体(LakeHouse)的基础
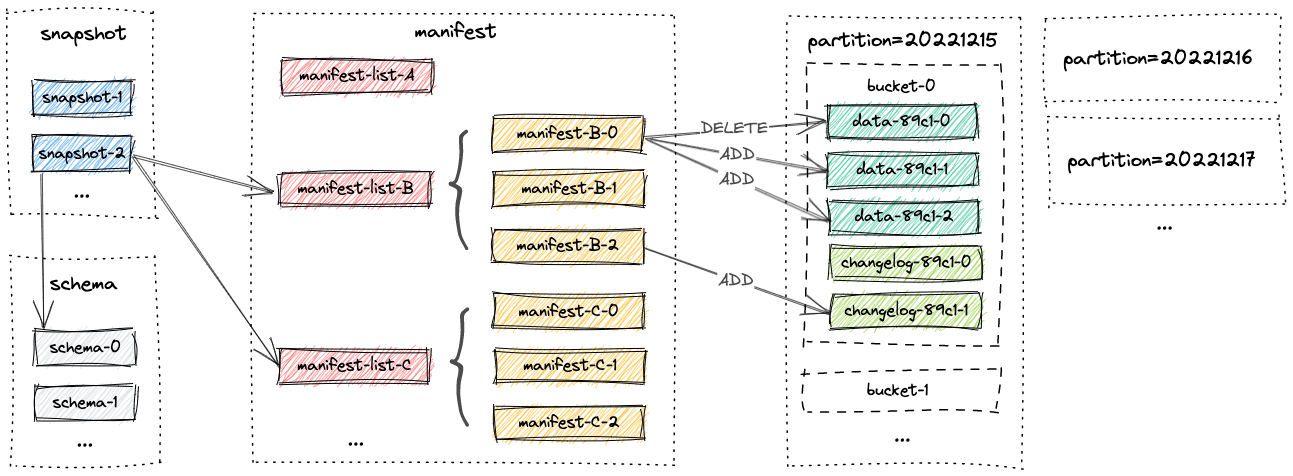
准实时:Paimon
实时更新能力支持好,在准实时(分钟级)场景大展拳脚。
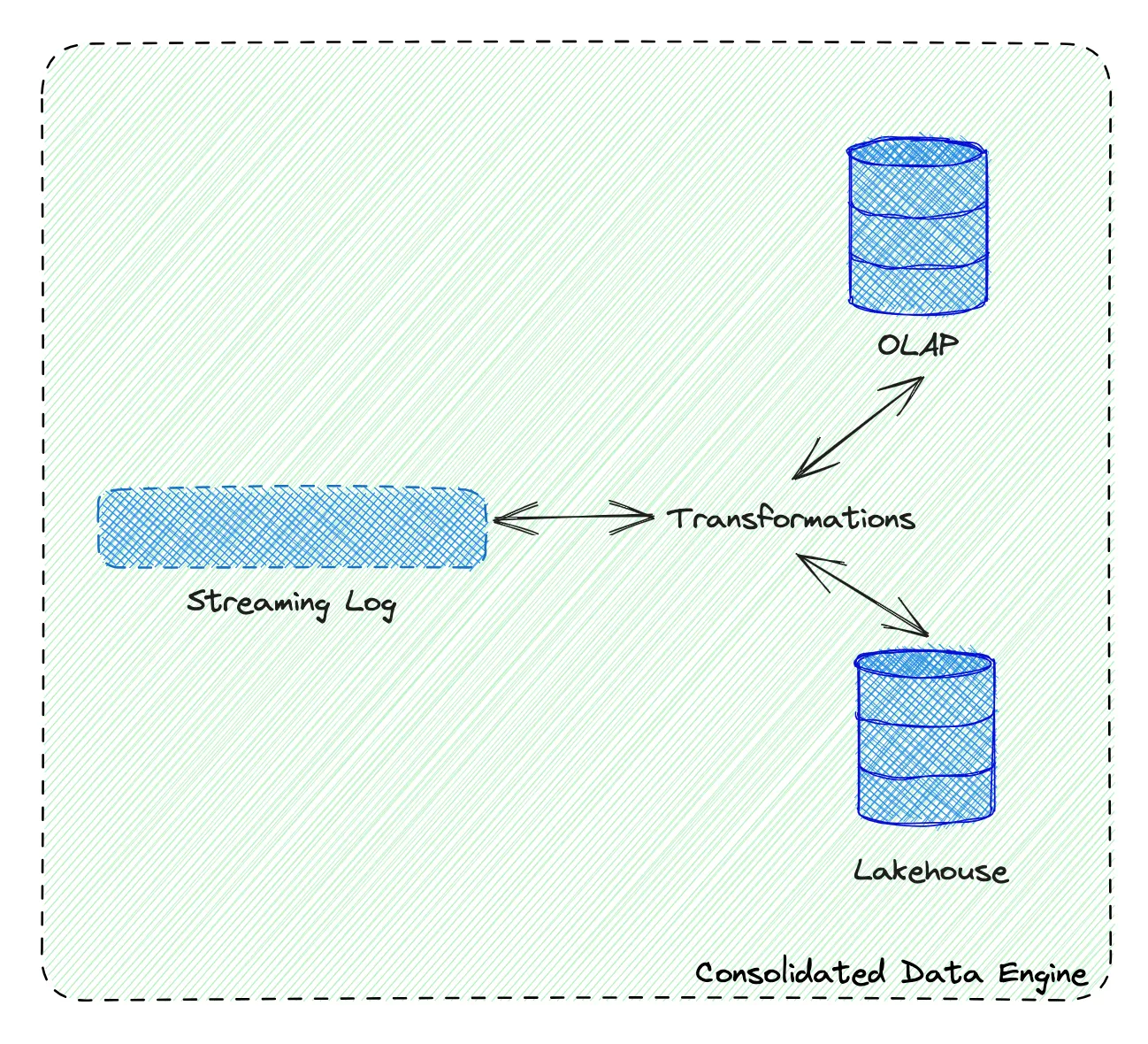
流存储
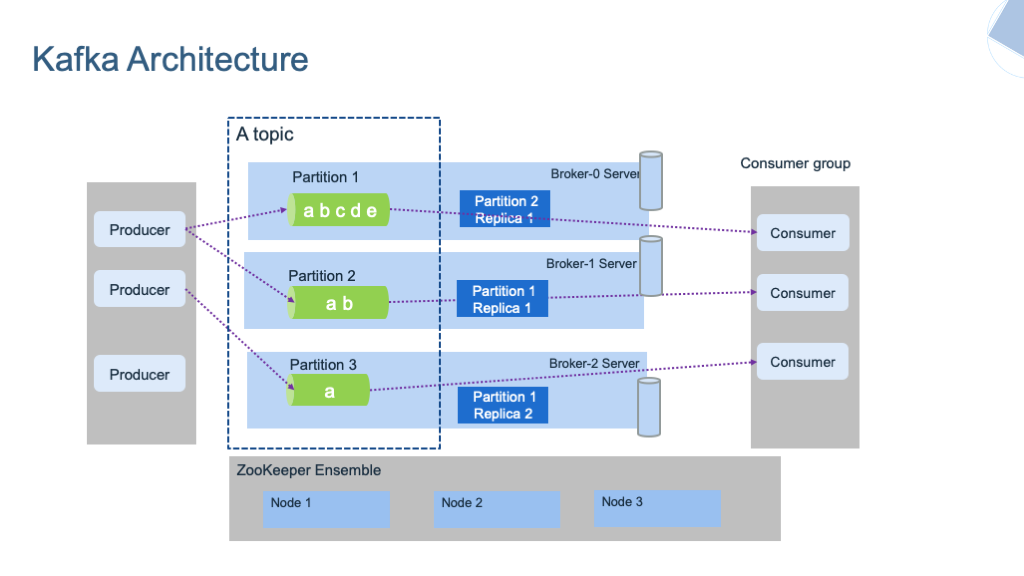
消息队列:Kafka
常用于实时数仓的中间层,结合Flink两阶段提交,读已提交(read-commited),可以保证exactly-once。
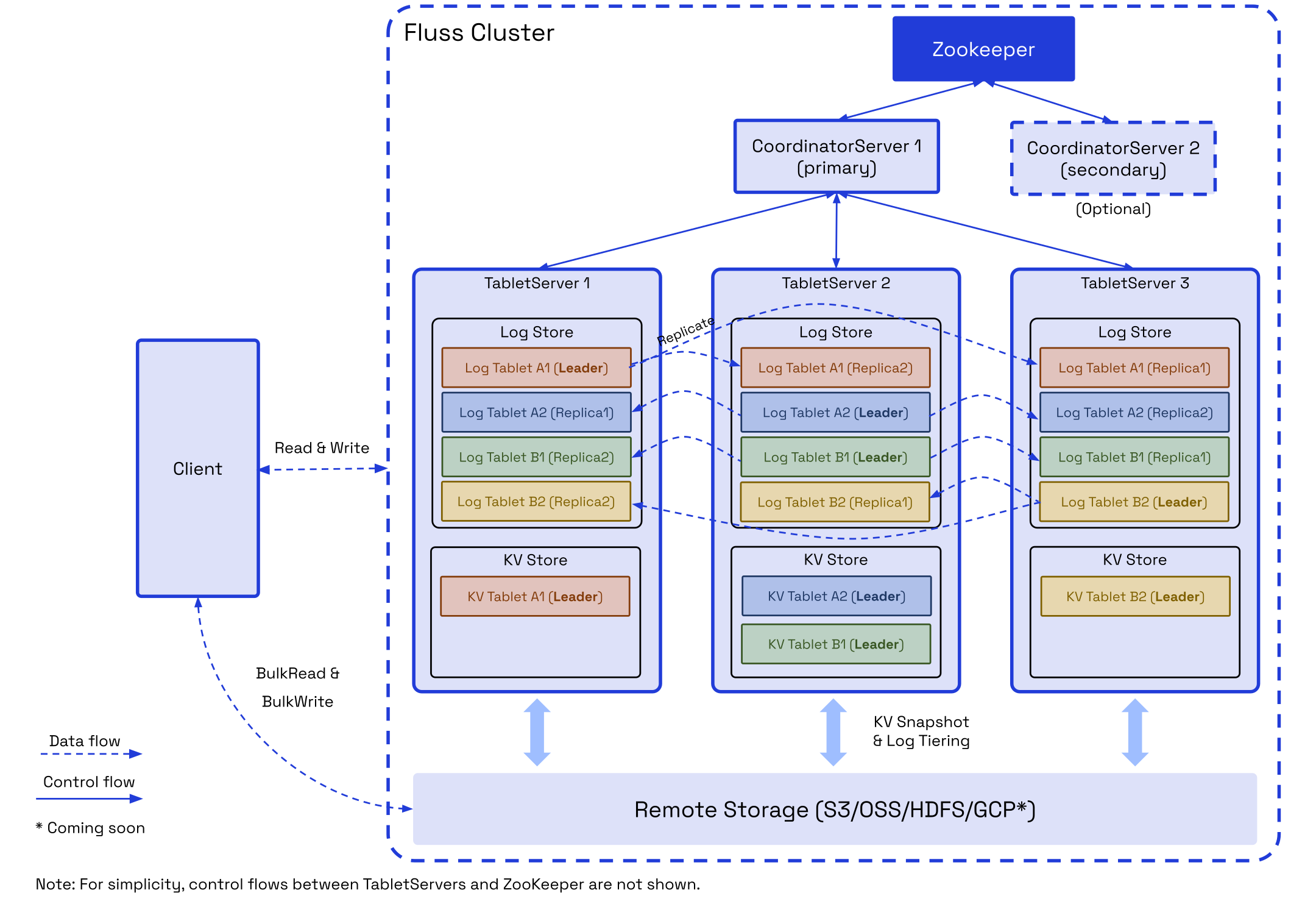
流分析:Fluss
由于kafka更新、查询等能力上的不足,Fluss有望替代成为实时数仓新的中间存储层。
数据计算
计算框架:MapReduce
现在SQL已经统治了大数据开发,没有机会写MapReduce程序,但其中的思想还是值得学习的,分而治之。
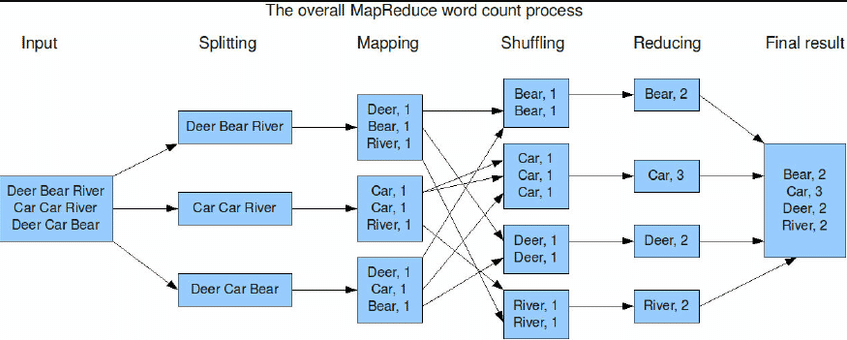
数据仓库:Hive
Hive的一大贡献是用SQL统一的编程模型,但由于其运行得太慢,现在对其最大得感知就是Metastore了(Hive表)。

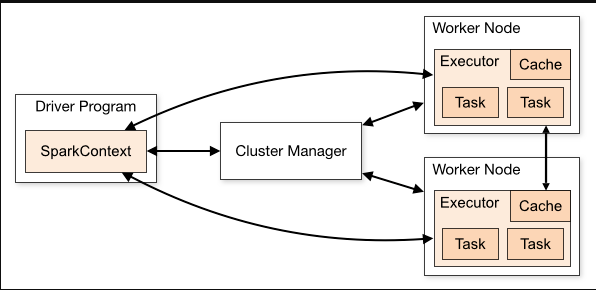
计算引擎:Spark
离线计算现在已经很成熟了,自适应查询执行(Adaptive Query Execution)、动态分区裁剪等能力让你只需专注于SQL逻辑实现。从JVM迁移到原生引擎上提高查询速度是一技术方向,如Gluten。
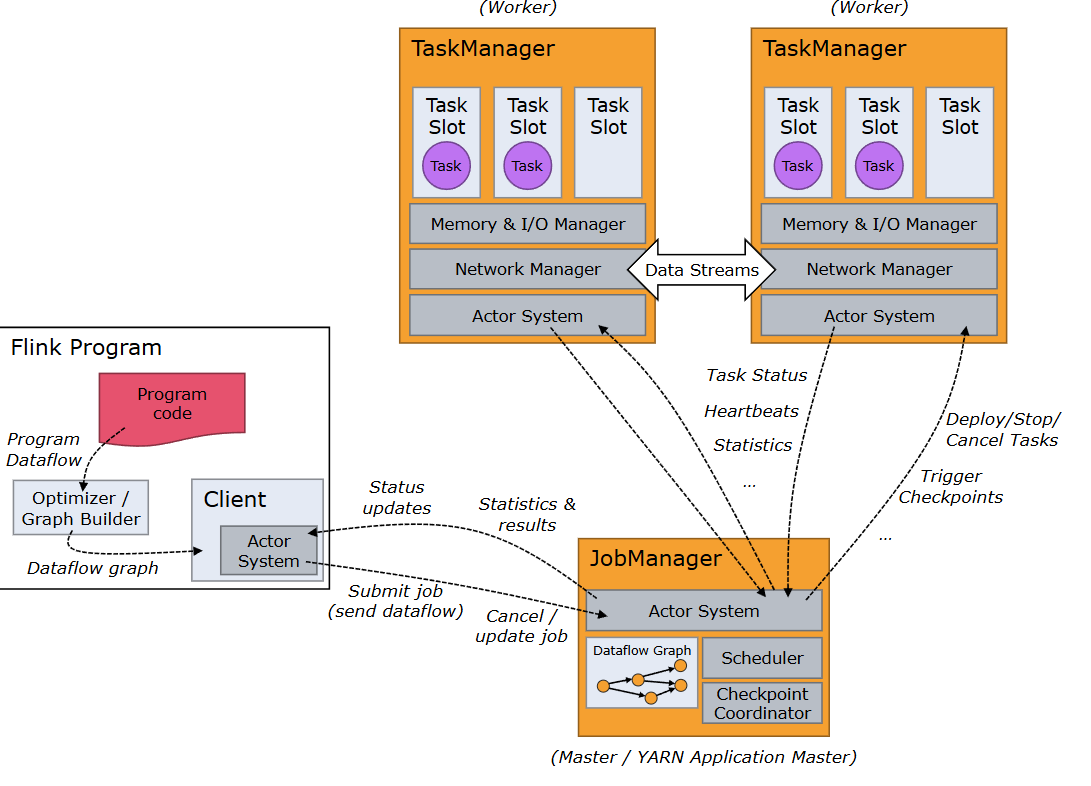
流计算:Flink
计算做了太多事情,导致状态过大,需要和存储一起去解决问题。 参考论文实现The Dataflow Model:
What results are being computed. => Transformation
Where in event time they are been computed. => Window
When in processing time they are materialized. => Watermark and Trigger
How earlier results relate to later refinements. => Discarding, Accumulating, Accumulating & Retracting.
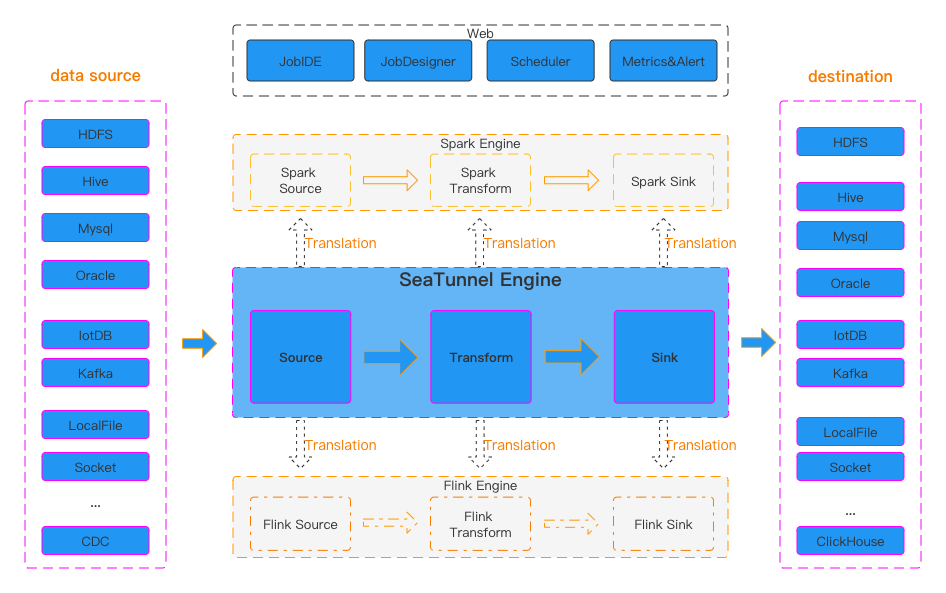
数据集成: SeaTunnel
如果只使用Flink,那FlinkCDC是一个好的选择,但没有银弹,需要按照相应的场景选择合适的方案。
数据服务
NoSQL:HBase
KV存储,可以当成实时维表使用,同时也适用于用户标签等在线场景。
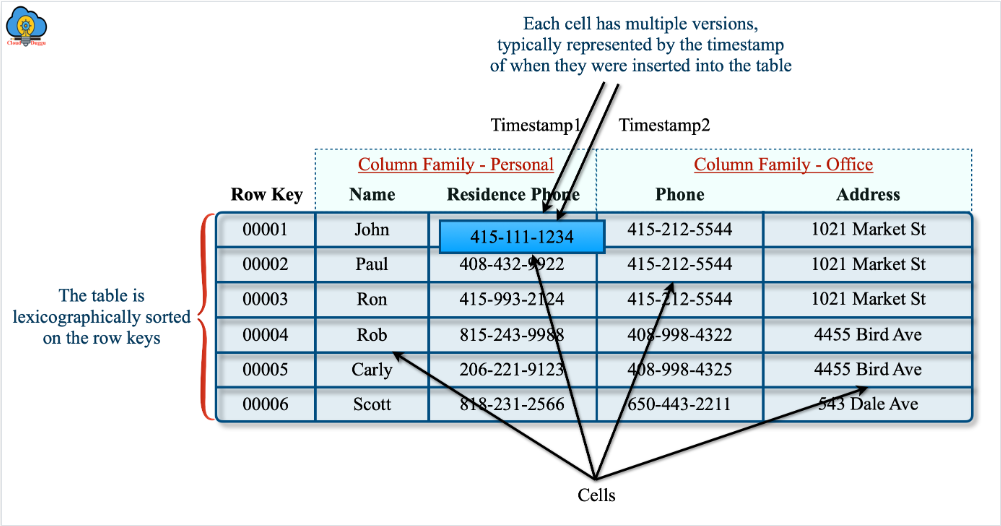
OLAP:Doris
如果说Hadoop架构是庞大、松散但极具韧性的民兵组织,那OLAP系统采用MPP架构就是高度专业化、训练有素的特种部队,但优化查询性能最好的方法还是减少数据量。
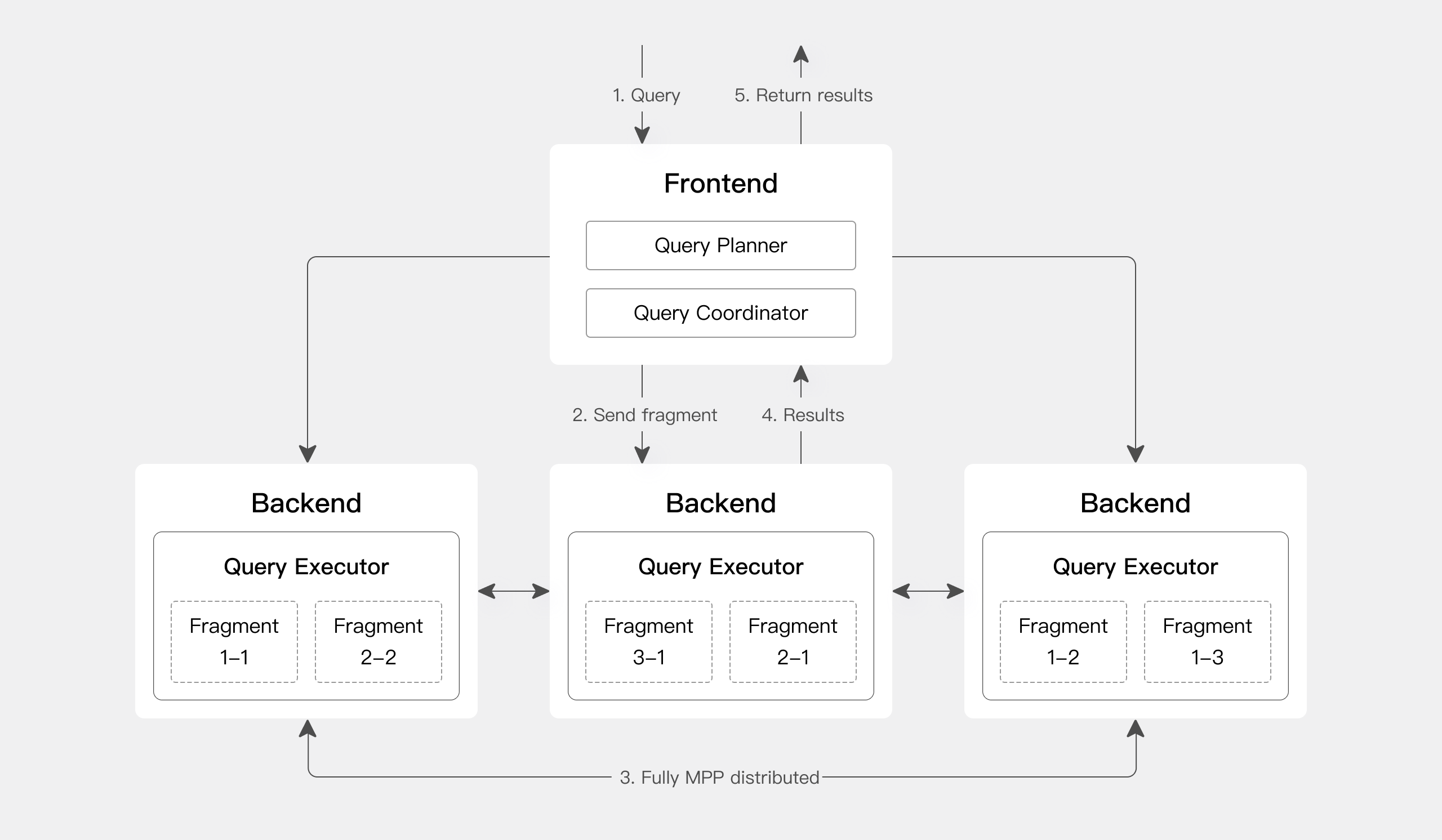
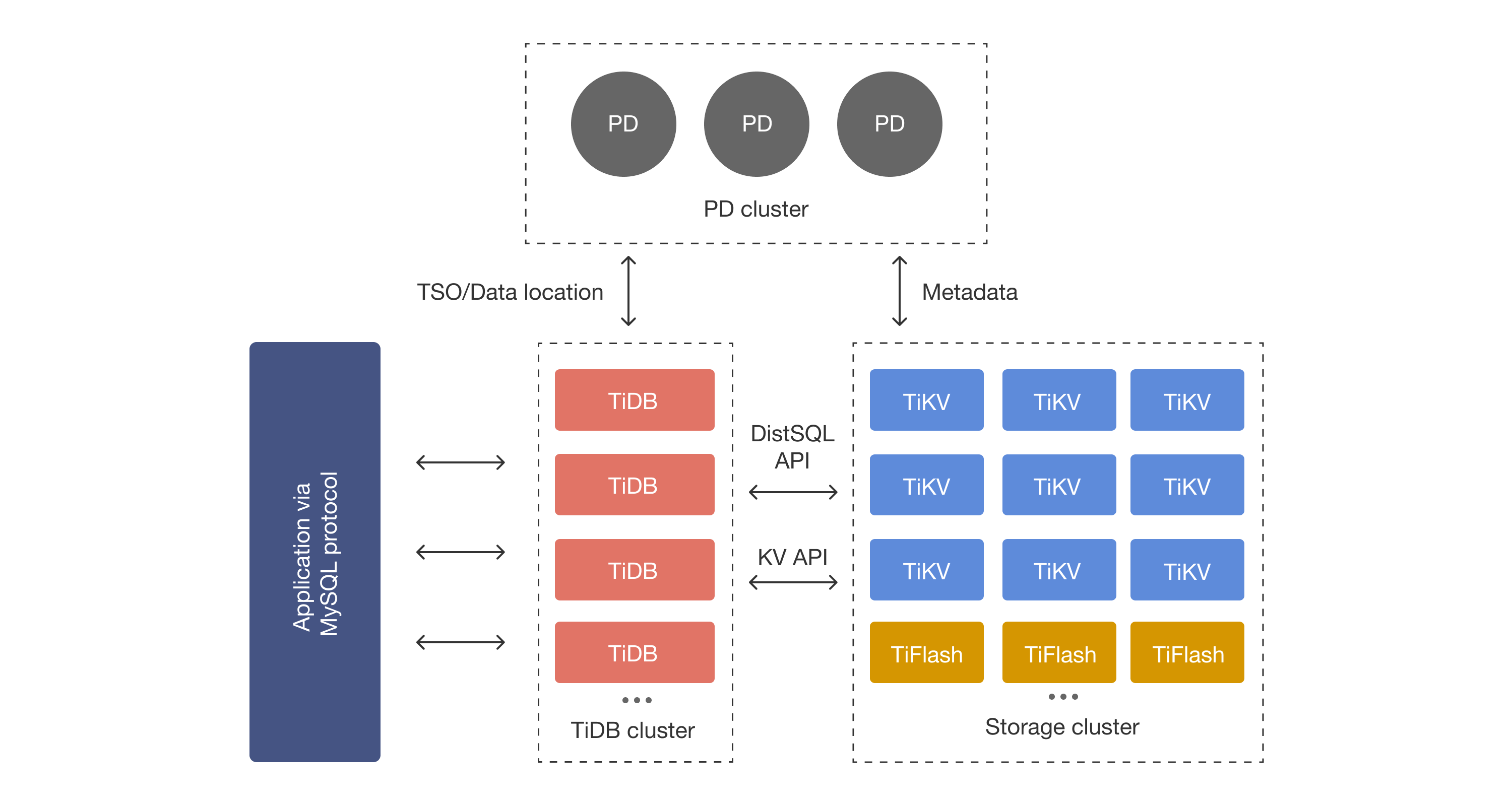
HTAP:TiDB
直接从数据生产上游OLTP出发去支持OLAP,简化数据架构,后端数据一个团队,分析需求简单情况下可以考虑使用。
数据可视化
数据开发的工作就是为各种分析需求而生,数据可视化的价值非常直观,容易被业务方买单,但如何影响决策,价值闭环还是很难说清楚。
 其他组件
其他组件
集群管理:YARN
集群管理对数据开发人员最强的感知可能就是队列跑不动数了,其实业务资源会有明显的潮汐现象,利用k8s进行在离线混部,进行动态资源分配是趋势。
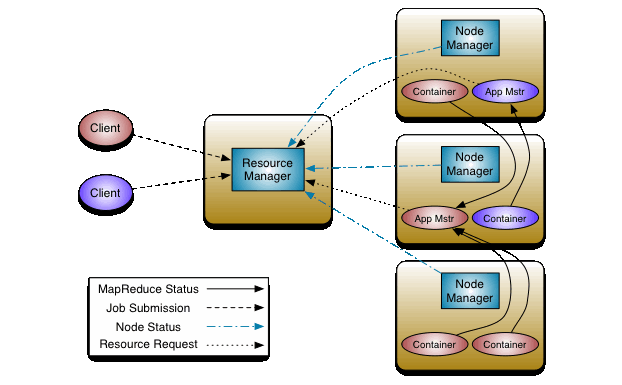
任务调度:Airflow
流计算的成本还是比较高的,未来的趋势是基于批处理引擎低延时调度+增量计算的方式的统一架构,能够在分钟级延迟的数据新鲜度同时保持较低的成本。
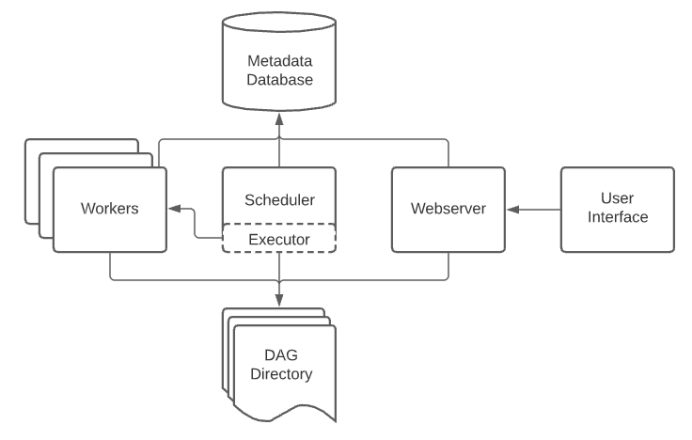
元数据管理:Gravitino
实时开发的时候每次都建立一个元表是一个比较麻烦的事情,统一catalog就避免了此麻烦,但其实数据开发最大的痛点还是数据口径问题,数据血缘和AI工具相结合应该可以解决这个问题。
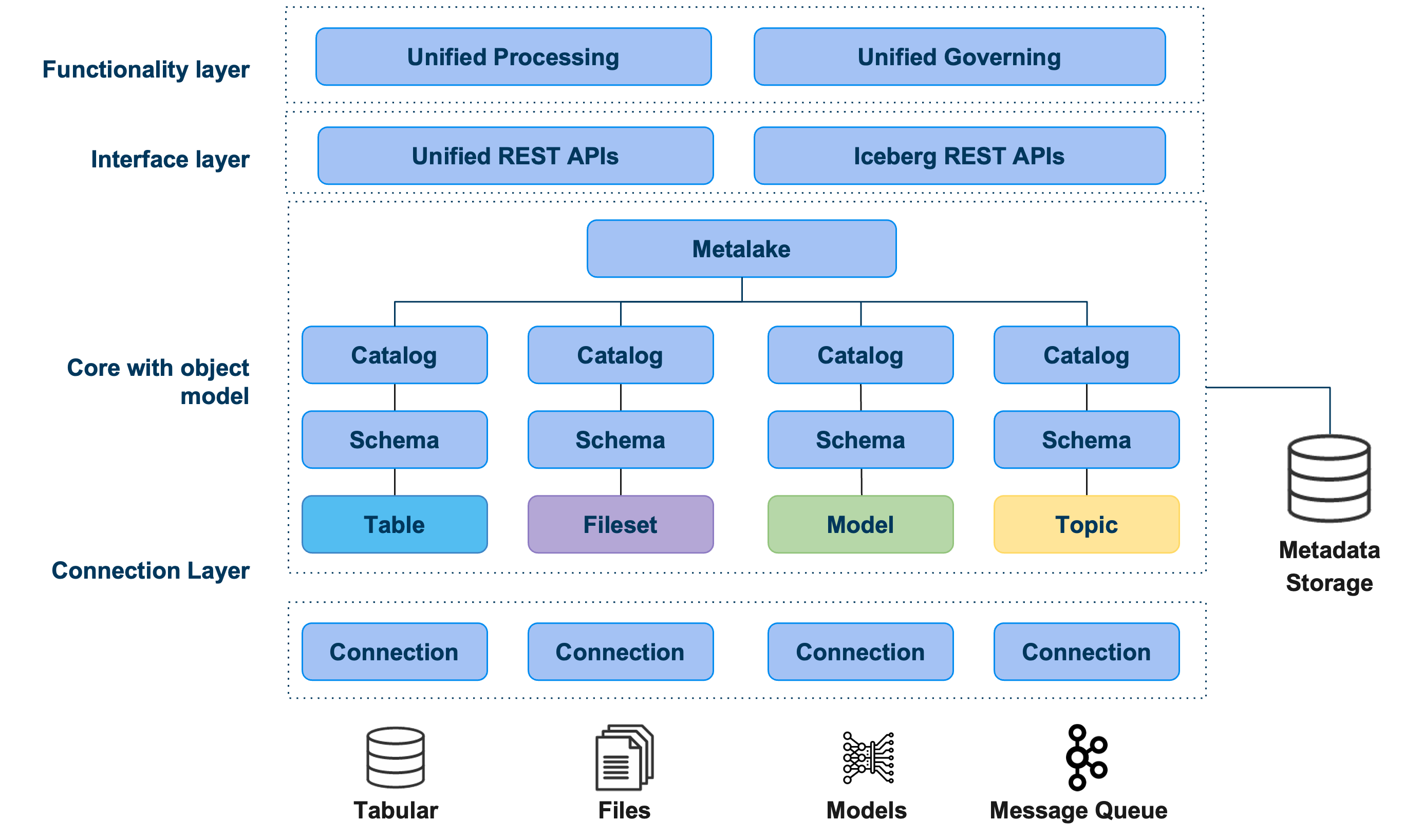 Gravitino
Gravitino
总结
大数据生态圈异常复杂,要完成一个数据需求,需要很多大数据组件相结合,但随着大数据开发平台的逐渐成熟,已经屏蔽了很多底层的复杂性, 开发门槛已经比较低了。以后的数据开发也许又会回到数据库时代,整个数据流就像一个巨大的数据库,内部通过统一的接口进行交互,外部提供一个统一的SQL开发入口,甚至可以直接利用AI交互,数据的价值将更好地体现~