Flink SQL回撤机制与问题
之前一直只是粗略地知道Flink SQL的回撤机制是为了保证数据的正确性而引入的,但没有想到它还引入一些不易察觉的副作用,对实时盯盘等要求高的场景需要花费额外的工作处理问题,如changelog乱序、中间错误结果暴露等。本文就讨论了具体的问题以及解法。
回撤机制
批 SQL 是查询一次出一个静态结果,但流 SQL 是查询在不断变化的输入上持续维护一个结果——上游一变,下游已经发出去的旧结果就错了,必须有机制告诉下游"我之前说的那条作废"。这就是回撤的本质:它不是性能优化,是流式 SQL 维护正确性的最小成本。
考虑统计词频分布的SQL语句:
SELECT cnt, COUNT(cnt) as freq
FROM
(
SELECT word, COUNT(*) as cnt
FROM words
GROUP BY word
) t
GROUP BY cntFlink SQL 回撤(Retraction又名Changelog)机制在接受到 1 条更新操作时会同时下发 2 条消息到下游节点:update_before 和 update_after。下游分别处理两条消息,在结果上先减去update_before,然后再加上update_after,保证最终结果的正确性。
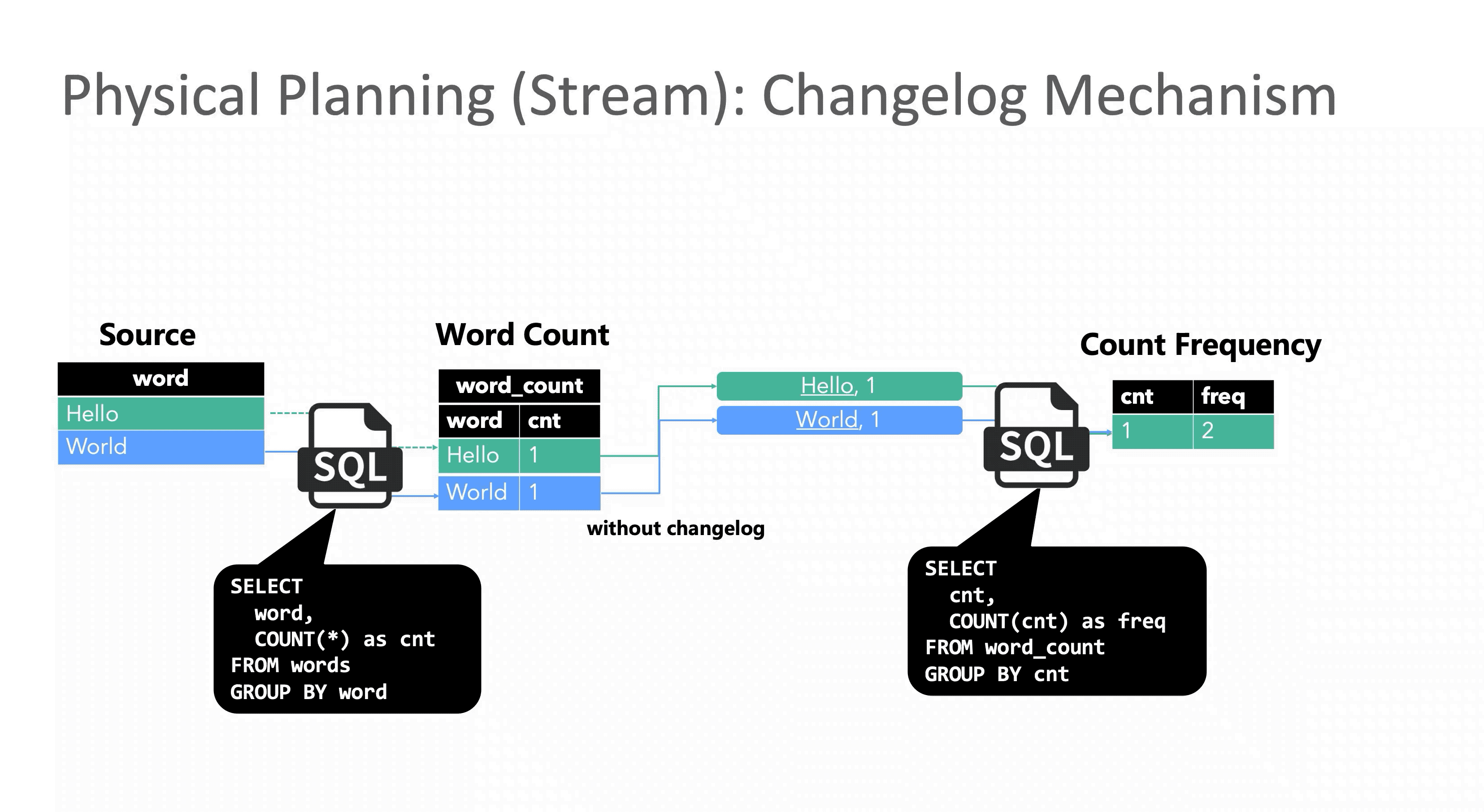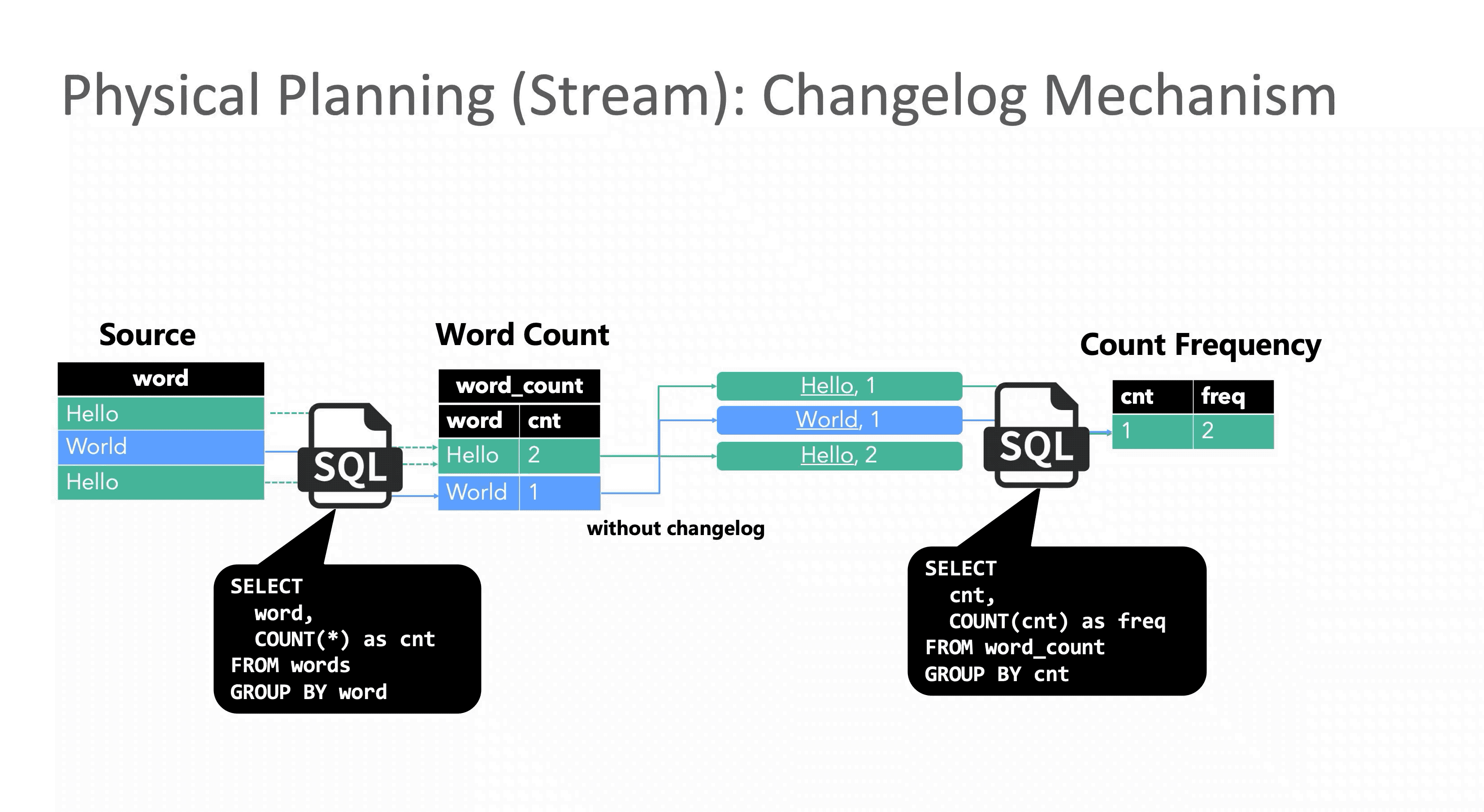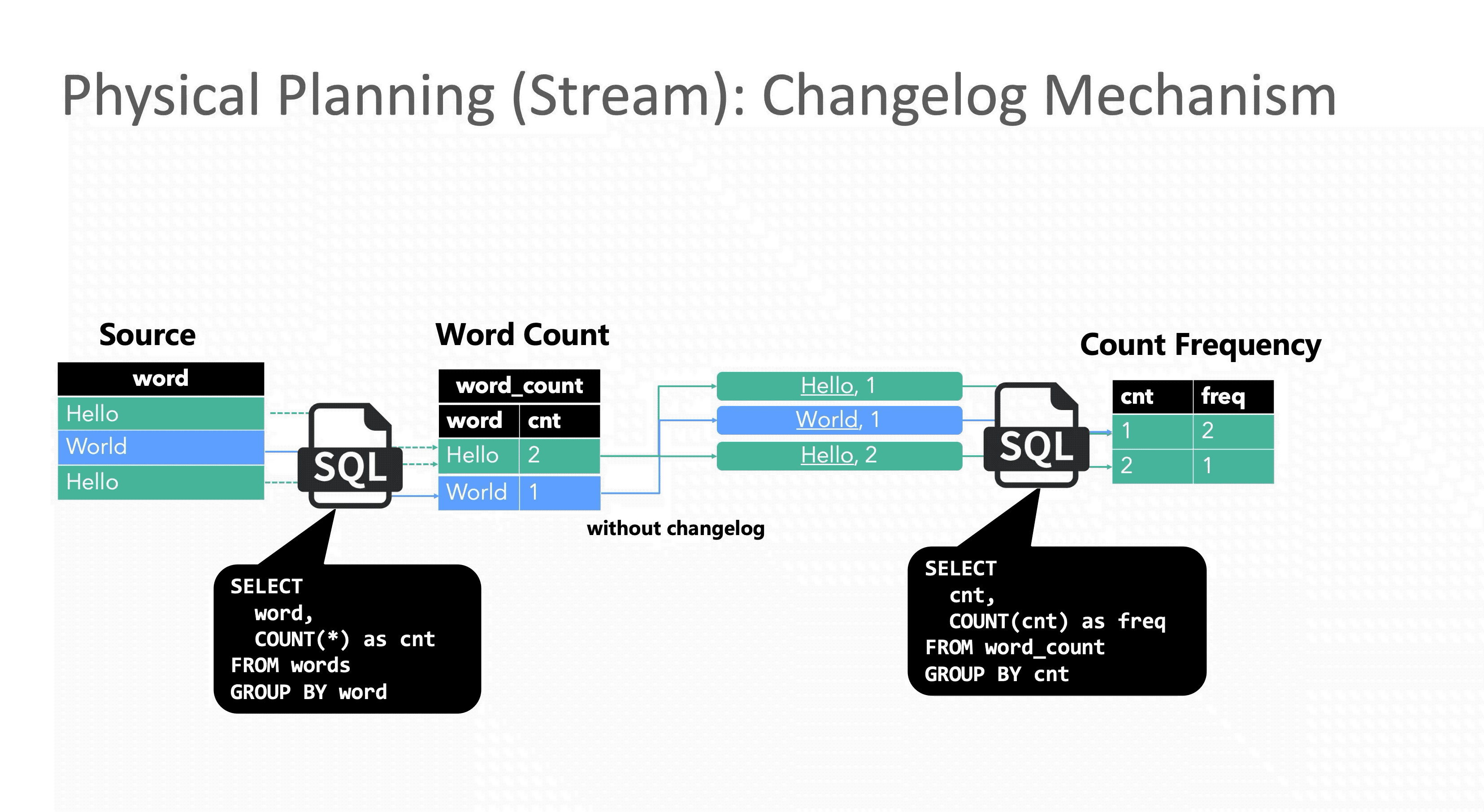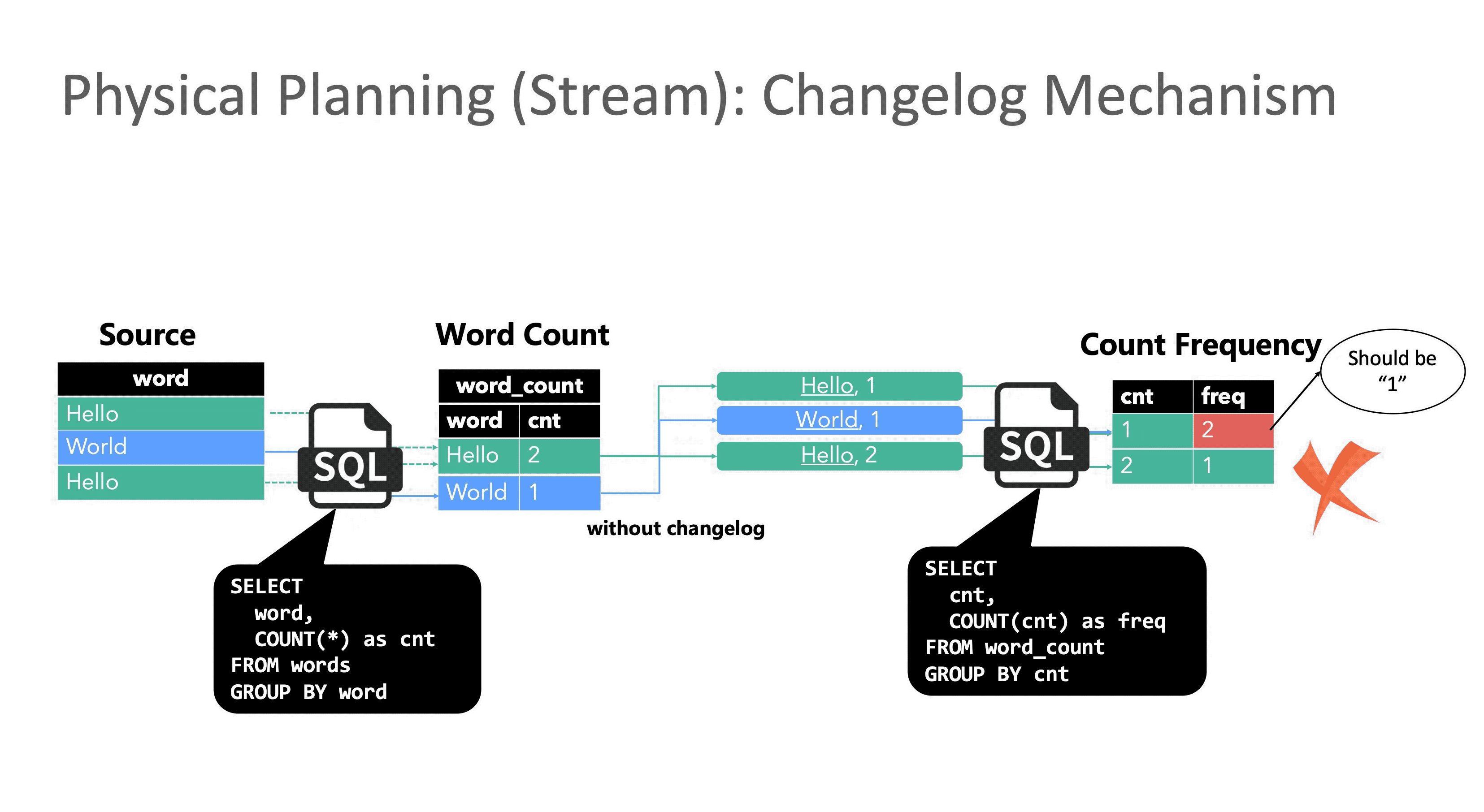
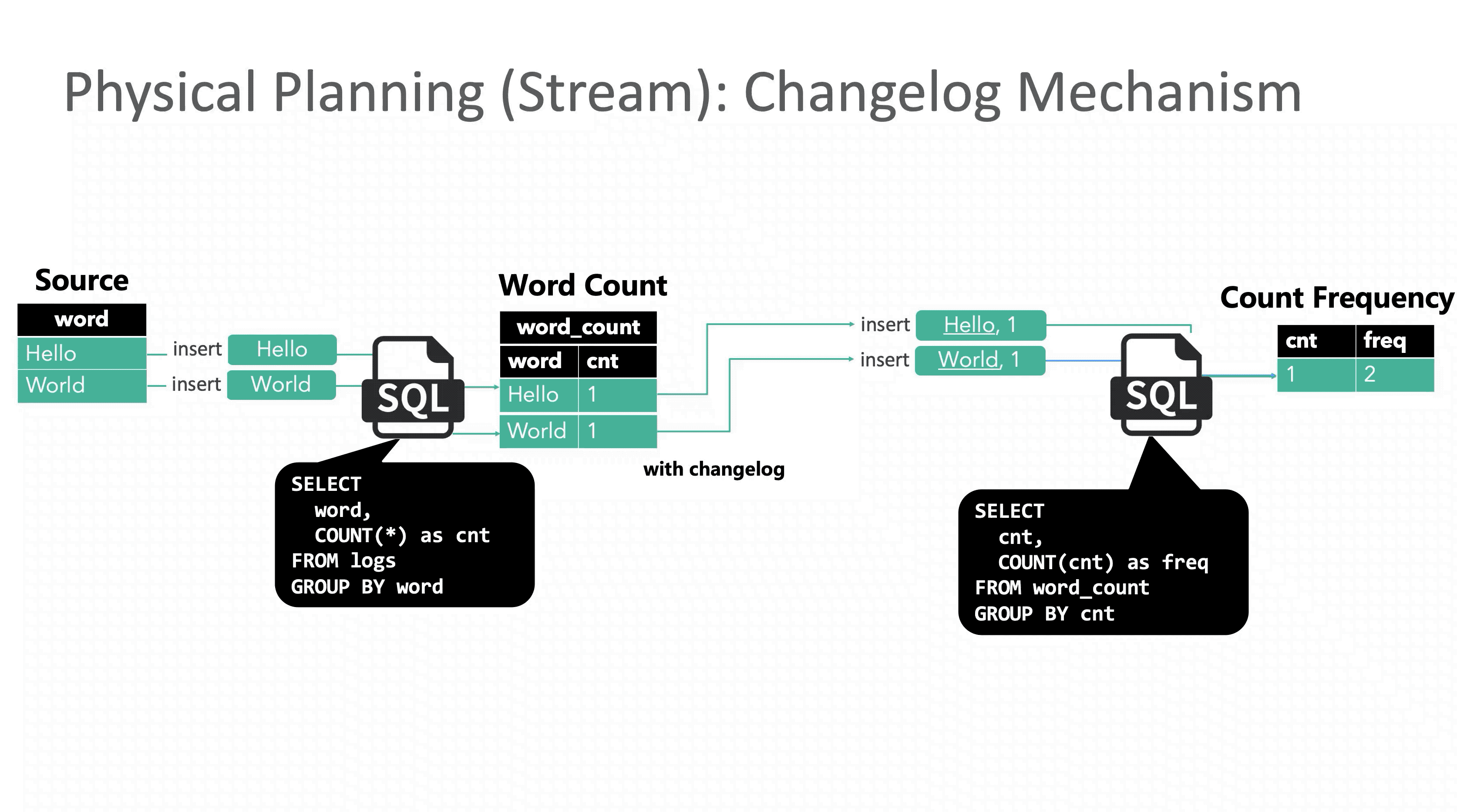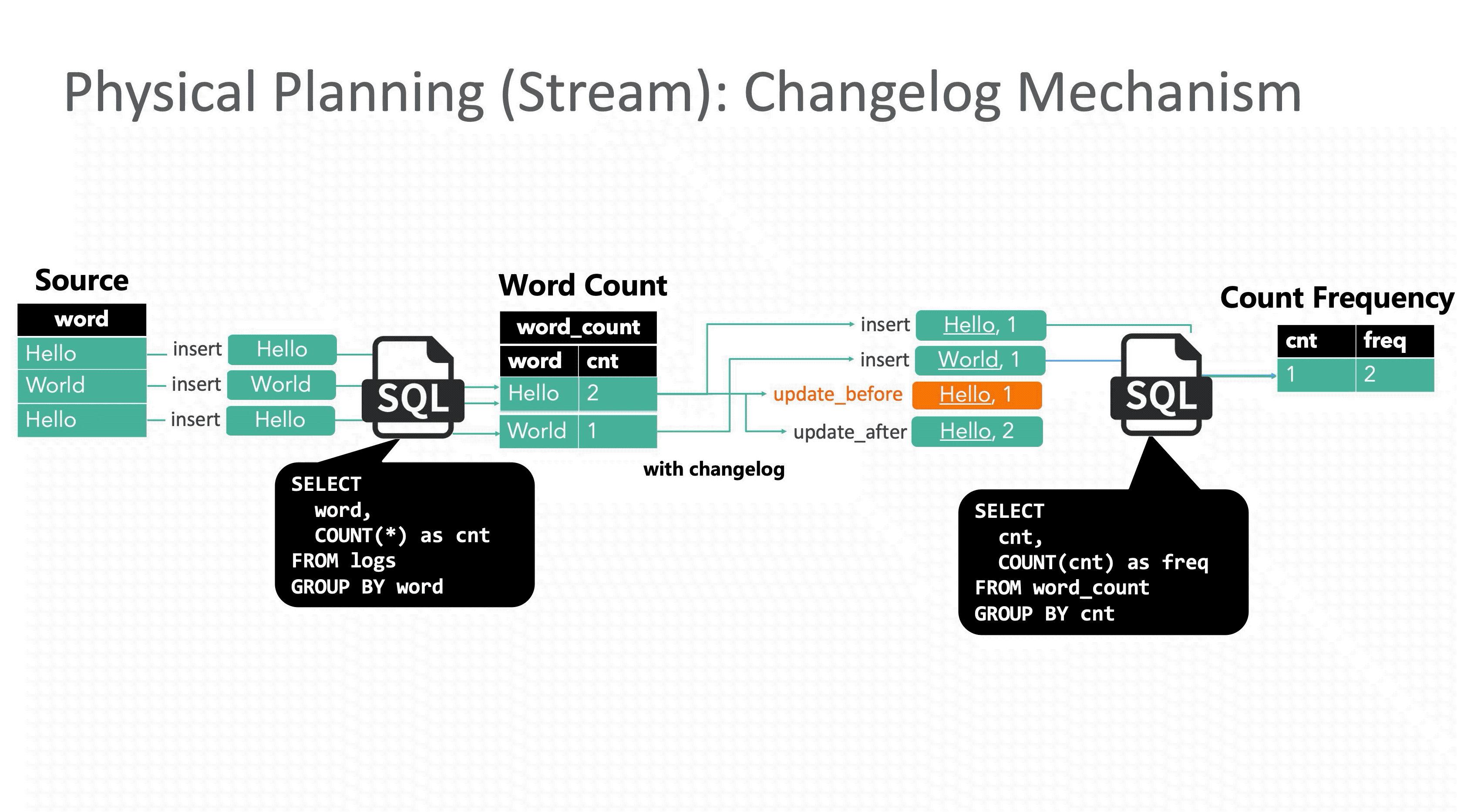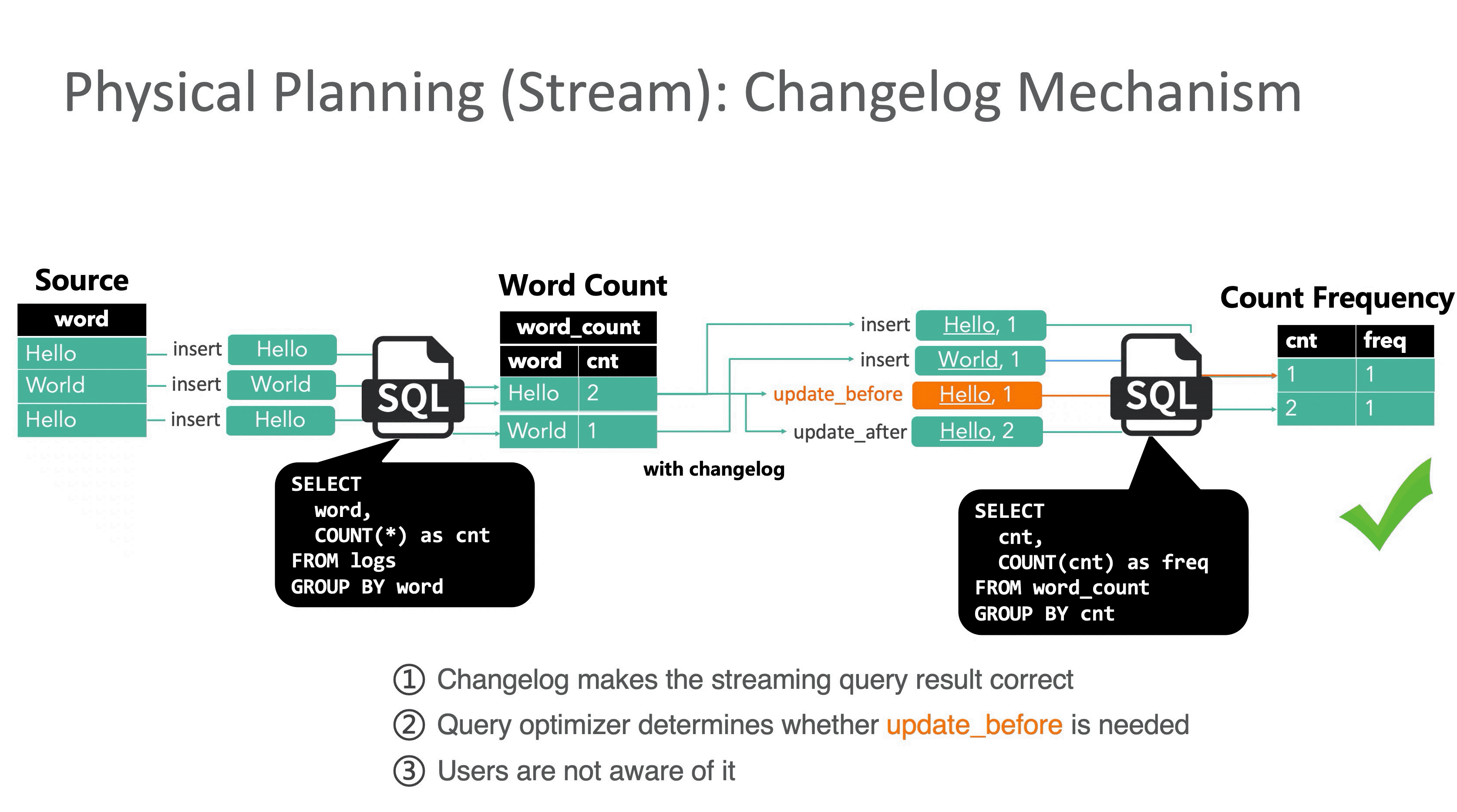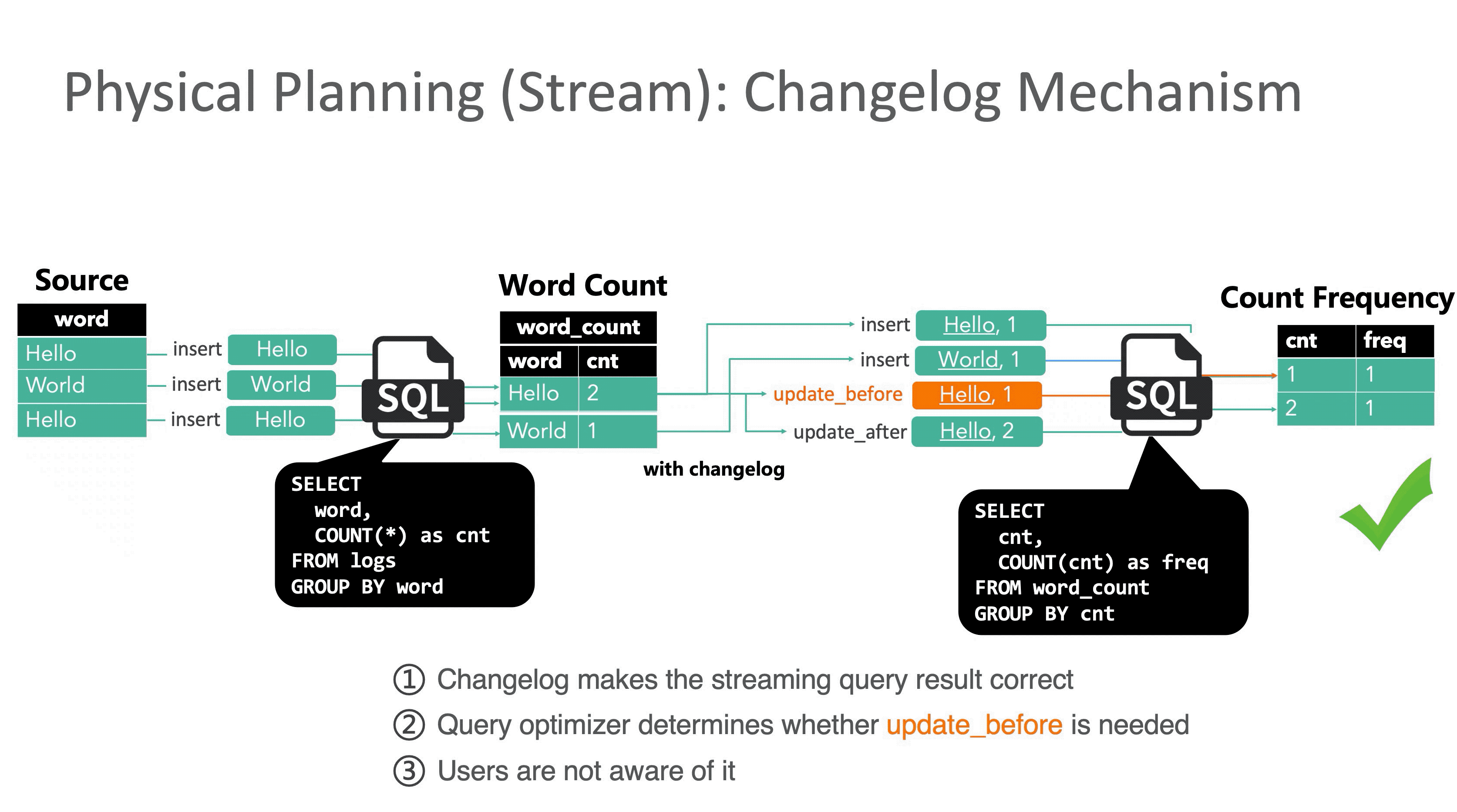
虽然回撤机制保证了结果的正确性,但引入的代价也不小,由于Flink是事件级流水线和单条事件原子性,表面看起来只是一条事件拆分成两条会导致数据膨胀,其实更严重的是原本应该原子执行的一次更新被拆成两步执行,就会遇到传统事务中的读未提交问题,下游读到中间错误的结果。与此同时在分布式环境里还需要解决消息乱序问题,保证最终一致性。
Flink不采用复合的更新消息主要原因有两个方面:
序列化简单:拆分的事件无论是何种事件类型都具有相同的事件结构。
分布式shuffle:即使使用复合UPDATE事件,在数据处理(例如Join、聚合)过程中,有时仍需将其拆分为单独的DELETE和INSERT事件进行shuffle,故保持全程一致。
Changelog乱序:引擎解决
我们来看一个Changelog乱序的一个例子:

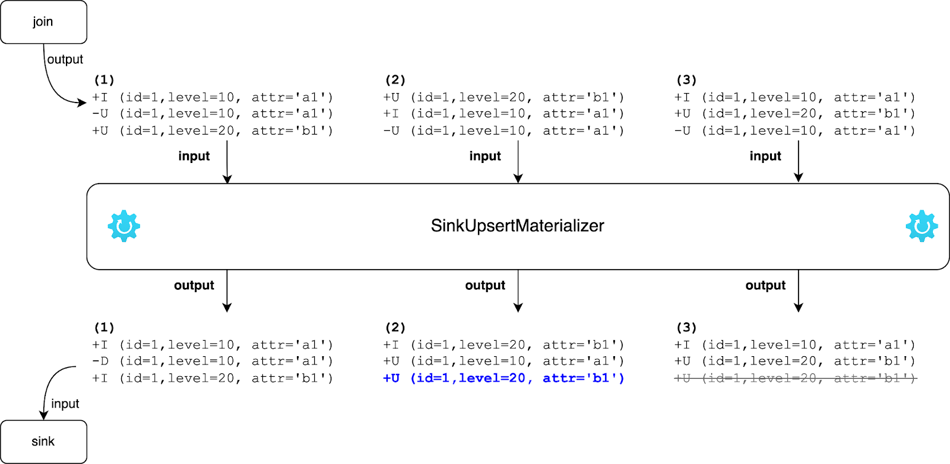
有两个Source, 通过外键双流关联后输出,由于关联键和s2的主键不一致,在分布式环境shuffle后,下游sink算子会有三种顺序:
情况1的事件序列与顺序处理中的事件序列相同,最终结果符合预期:(id=1, level=20, attr='b1')。
而情况2和情况3为乱序情况,如果没有其他措施,将从外部存储不正确地删除id=1的行,不符合预期。
为此,Flink 引入了SinkUpsertMaterializer算子,将changelog进行重排序,保证最终结果的正确性,具体原理可以参见Changelog事件乱序处理原理,本文就不赘述了。
现在的SinkUpsertMaterializer的"rollback"语义需要保留完整历史才能正确处理回退,会有严重的性能瓶颈,所以社区在FLIP-558 中将选择权交还给用户,提出了ON CONFLICT语法显式声明如何处理冲突,解决状态膨胀问题。
然而中间结果暴露其实对用户的体感更大:监控大盘上看到本该单调递增的指标突然下降。Flink在FLIP-558中承认了语义缺陷,并提出利用watermark作为分布式屏障做 compaction(永远不在 UB/UA 之间生成、永远不越过记录),用一定的延迟换取内部的一致性。但现阶段只能依靠业务侧的一些手段处理,我们具体来看两个例子。
错误的中间结果:业务承受
现象
聚合时指标下降:当求和计算收到更新消息时,由于更新消息被拆分成了update_before和update_after, 当聚合算子收到update_before时,它会先回撤之前的结果-U,再发出回撤之后的结果+U,这里就会出现指标突降的现象:原本应直接 3 -> 4,但中间出现了 2 这个错误值 。后续收到update_after的消息后,才更新为预期结果。
关联时关系为空:类似的,Join算子对拆分后的update_before会撤回之前的结果后,会发出一条关联为空的消息,代表没有关联上,这时就是导致下游查询时会出现突然没数的情况。

虽然在flink中开启mini batch可以很大程度缓解类似的中间错误结果,但对数据很敏感的场景(如实时监控)还是需要根本上杜绝这种现象,这里介绍两种方法。
方案
写入处理:版本字段
实时场景中最终结果一般时写入类似Doris这样的OLAP引擎供用户查询,因为Doris是支持更新的,所以写入时默认会忽略-U消息(sink.ignore.update-before参数控制)。同时我们在需要保证递增的字段设置为sequece_col,保证只有较大值可以替换较小值,避免中间结果写入。

Doris的版本列问题就是不太灵活,只能按照一个字段对比,但实际中在进行复杂关联聚合后,不太好选取版本列字段,如既要保证多个指标递增,又要保证多个关系递增,就不太好设置版本字段了。
Apache Paimon的部分列更新机制能定义多个版本字段,可以比较灵活的设置更新方式,可以解决多字段需要保证递增的场景。
二次处理:自定义算子
最简单的方式就是在输出的最外层添加一个聚合算子,将需要保持递增的指标取max,其余指标取last_value即可。但Flink 2.1之后引入了Proccess Table Function自定义算子的能力,可以获取到消息的变更类型和自定义状态,可以让我们更灵活地处理变更:
自定义聚合算子,只对+I/+U输出更新后的状态,收到-U消息时只更新聚合状态,不输出结果,这样就避免了指标突降的中间结果。
自定义关联算子,忽略-U消息,只输出最新的结果,避免关联为空的消息输出。

具体实现可参考QFlink项目中的示例。
总结
本文介绍了Flink SQL为了结果正确性引入的回撤机制,并从引擎角度和业务角度讨论了回撤带来的问题及其解决方法,希望能对流计算有更深的理解。其实从业界流式计算的发展趋势来看,原子可见单元粒度大于单条 record 才是流式 SQL 正确性的真正底线。
在AI Coding时代,为什么还要用SQL,SQL只是为了让人更好的开发上手,现在可以AI写代码了,直接生成原始的Datastream代码,没有回撤问题,不是更简单吗?对此我的回答是,SQL生态不是一天建成的,软件都是分层的,上层要为下层屏蔽复杂性,只是Flink SQL还需要变得更好而已。