大数据性能调优
在分布式计算中,理论上没有数据倾斜问题,都可以靠加资源解决性能问题。与此同时,每个引擎都有其设计原理,需要针对其特性进行相应调优,本篇文章我们就从使用视角去看下如何优化性能。
数据倾斜
假设我们有两个表:订单表orders 和用户表users
CREATE TABLE orders (
order_id BIGINT COMMENT '订单ID',
user_id BIGINT COMMENT '用户ID',
amount BIGINT COMMENT '订单金额',
region STRING COMMENT '所在地区'
);
CREATE TABLE users (
user_id BIGINT COMMENT '用户ID',
user_name STRING COMMENT '用户名称'
);关联
现在我们需要关联订单表和用户表,获取用户的相应属性。
SELECT
o.order_id,
o.user_id,
u.user_name,
o.amount
FROM orders o
LEFT JOIN users u
ON o.user_id = u.user_id无意义Key
如果订单表中user_id 存在大量为无意义的数据,比如空值,这时我们可以直接忽略这些空值关联,将其随机打散:
SELECT
o.order_id,
o.user_id,
u.user_name,
o.amount
FROM orders o
LEFT JOIN users u
-- 空值转化为随机负数,保证关联不上且分散
ON IF(o.user_id is null, FLOOR(-1024 * random()), o.user_id) = u.user_id;热点Key
如果订单表中user_id 存在热点Key,比如user_id in (10001, 10002)占据了大部分订单,这时我们可以将热点key随机打散,维表对热点key复制后关联:
-- 第一步:提前找出热点Key
SELECT
user_id,
count(1) AS user_cnt
FROM
orders
GROUP BY user_id
ORDER BY user_cnt DESC
-- 第二步:对大表进行打散
WITH salted_orders AS (
SELECT
CASE
WHEN user_id IN (10001, 10002) THEN CONCAT(user_id, '_', CAST(FLOOR(RAND() * 1024) AS STRING))
ELSE CAST(user_id AS STRING)
END AS salted_user_id,
order_id,
user_id,
amount
FROM orders
)
-- 第三步:维表复制热点Key
,salted_users AS (
SELECT
CASE
WHEN user_id IN (10001, 10002) THEN CONCAT(user_id, '_', CAST(n AS STRING))
ELSE CAST(user_id AS STRING)
END AS salted_user_id,
user_name
FROM users
LATERAL VIEW EXPLODE(
CASE
WHEN user_id IN (10001, 10002)
THEN SEQUENCE(0, 1023) -- 热点 key 复制 1024 份
ELSE ARRAY(0) -- 非热点 key 只保留 1 份
END
) AS n
)
-- 第四步:进行Join
SELECT
o.order_id,
o.user_id,
u.user_name,
o.amount
FROM salted_orders o
LEFT JOIN salted_users u
ON o.salted_user_id = u.salted_user_id;聚合
假设我们现在需要按地区聚合计算uv和订单金额:
SELECT
region,
COUNT(DISTINCT user_id) AS uv,
SUM(amount) AS total_amount
FROM orders
GROUP BY user_id;如果订单表中region存在热点Key,我们可以拆分bucket进行两阶段聚合,以分担group key中的热点情况:
-- 第一次局部聚合
WITH agg_partial AS (
SELECT
region,
COUNT(DISTINCT user_id) AS partial_uv,
SUM(amount) AS partial_sum
FROM orders
GROUP BY region, MOD(HASH_CODE(user_id), 1024)
)
-- 第二次全局聚合
SELECT
region,
-- 由于相同的user_id将仅在同一分桶中计算,二次聚合直接相加即可
SUM(partial_uv) AS uv,
SUM(partial_sum) AS total_amount
FROM agg_partial
GROUP BY region;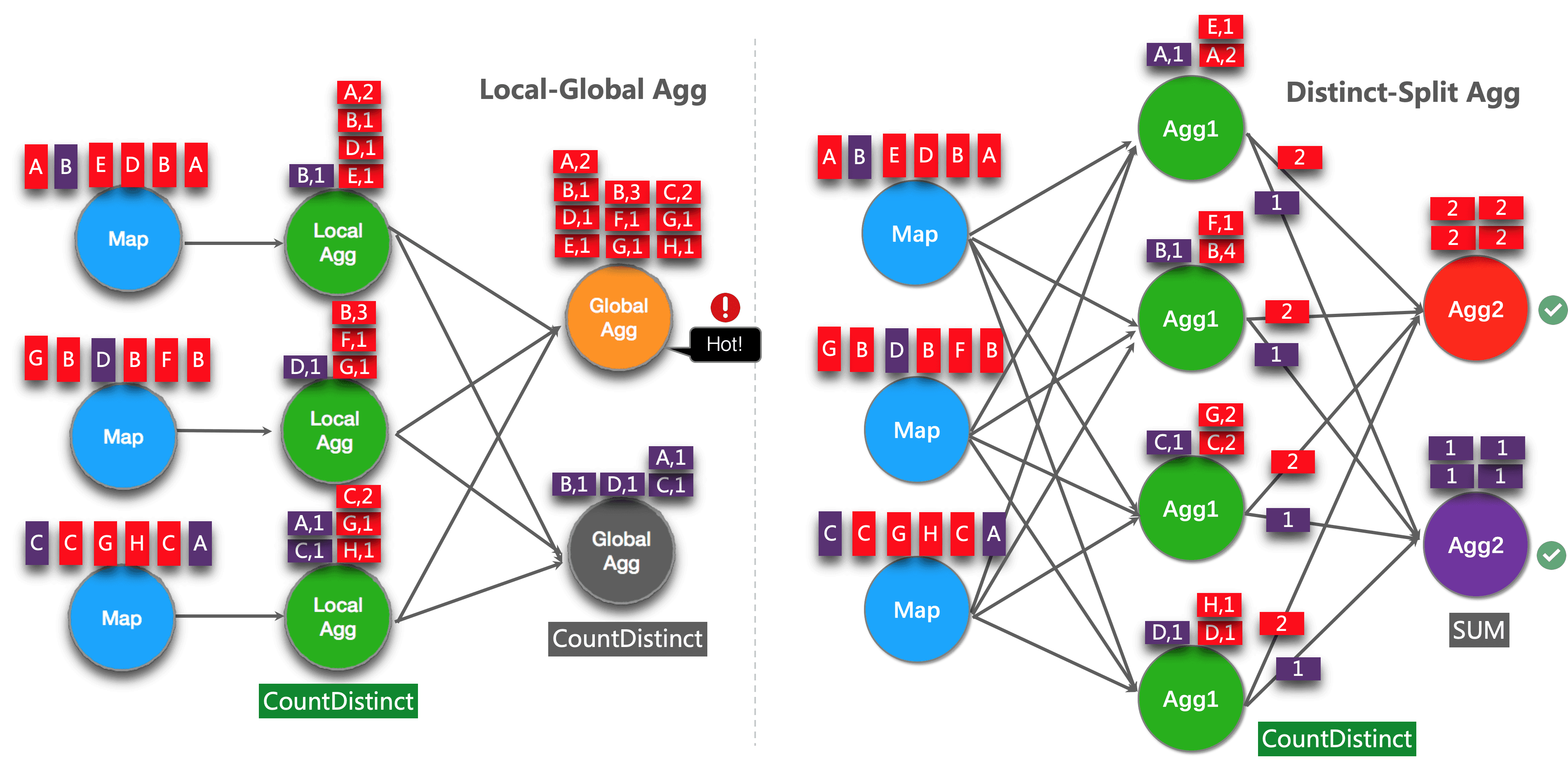
绘图加载失败
JOIN优化
Hash Join : 避免shuffle,Colocate > Bucket > Broadcast > Shuffle
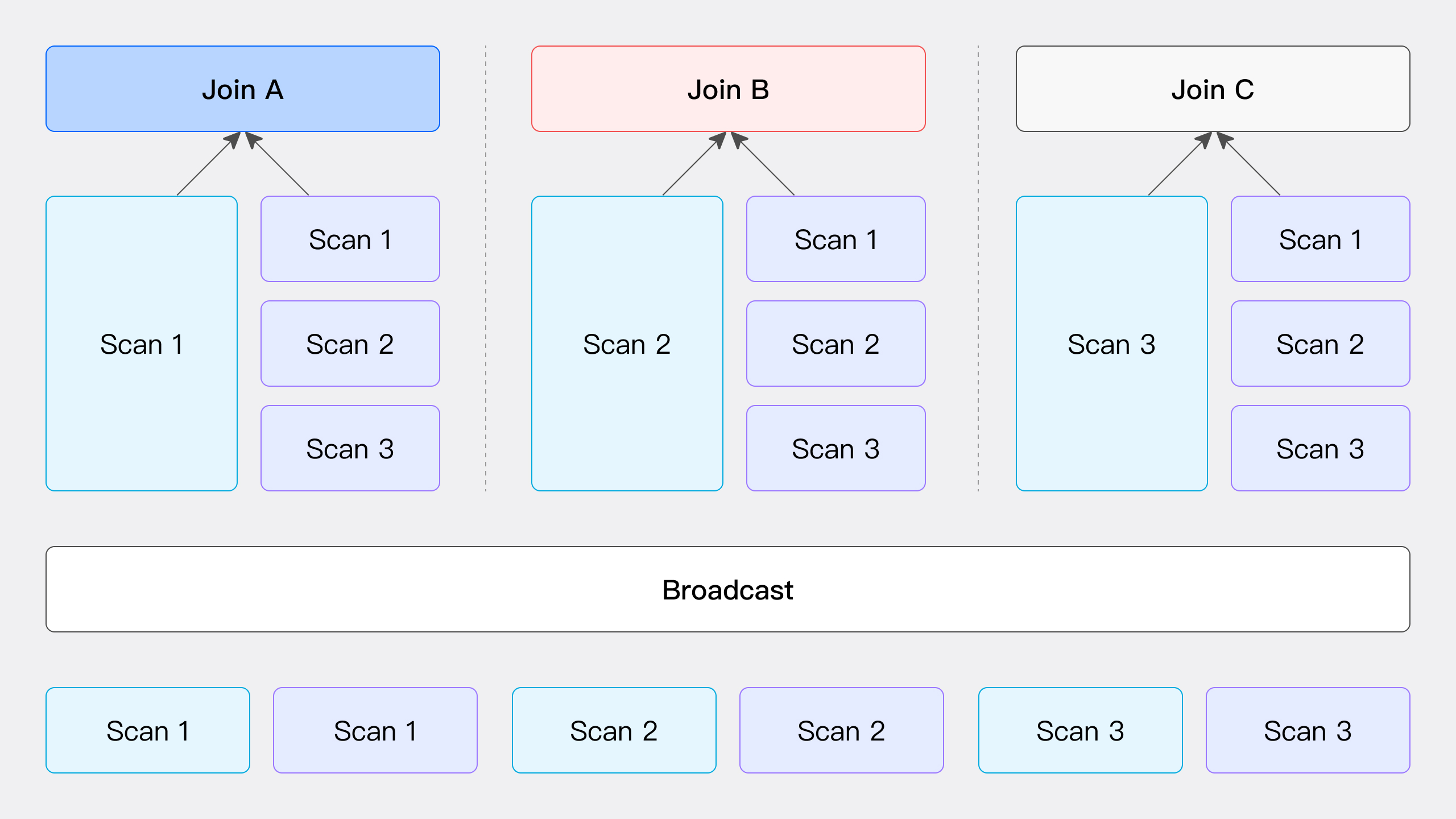
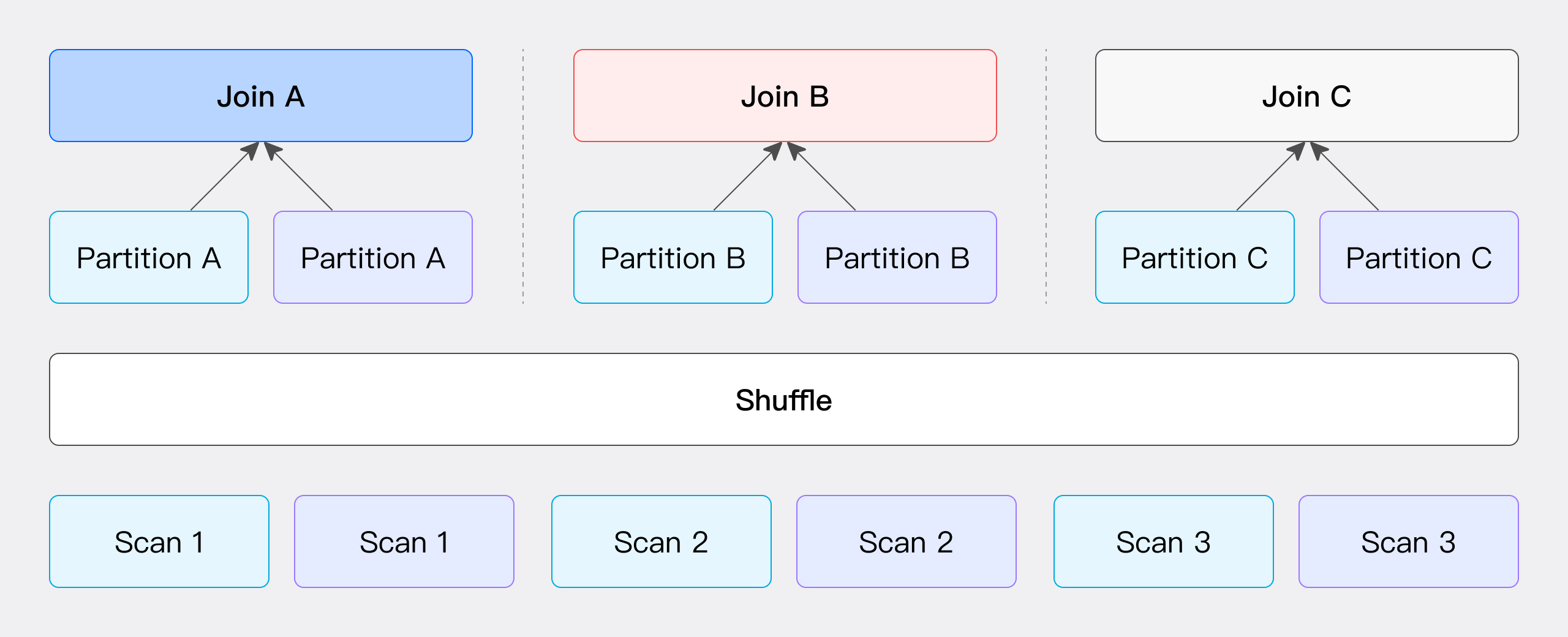
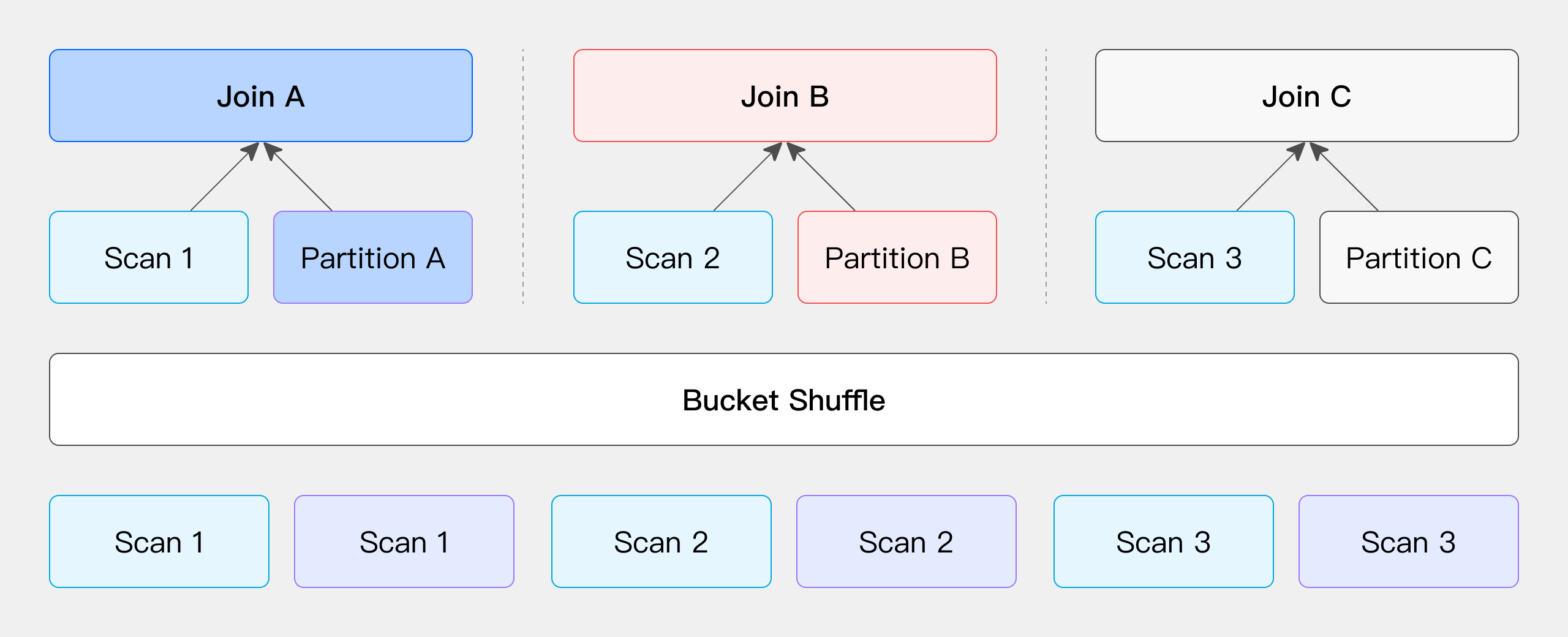
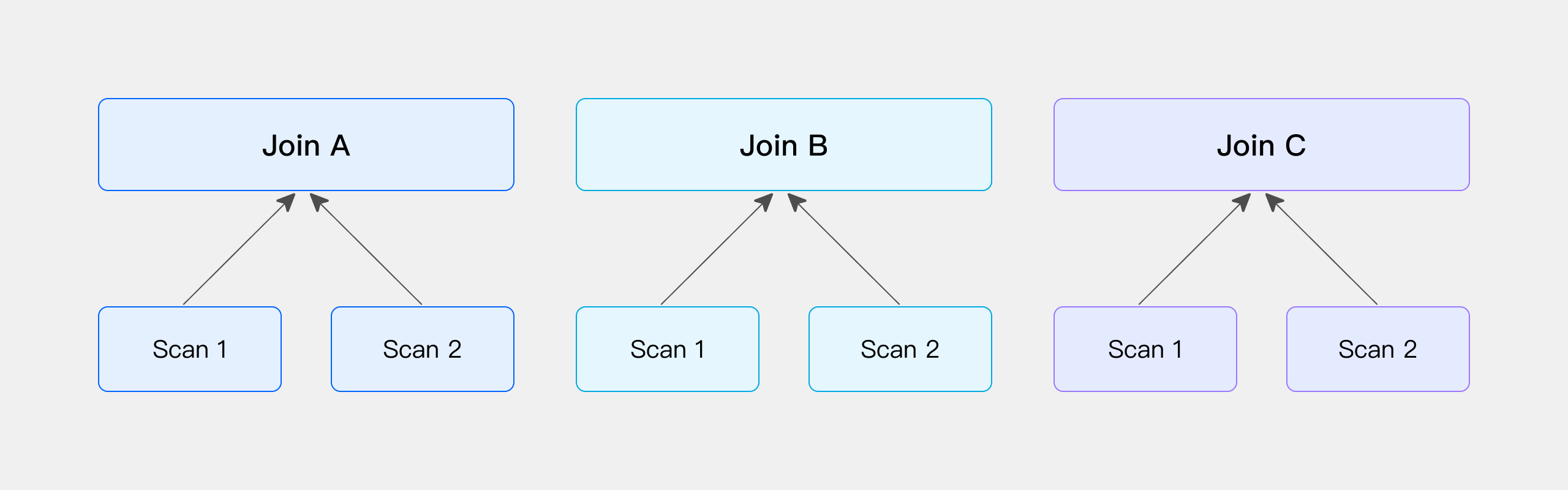
Runtime Filter: 根据join条件生成filter,进行动态下推,适合大表join小表的场景。
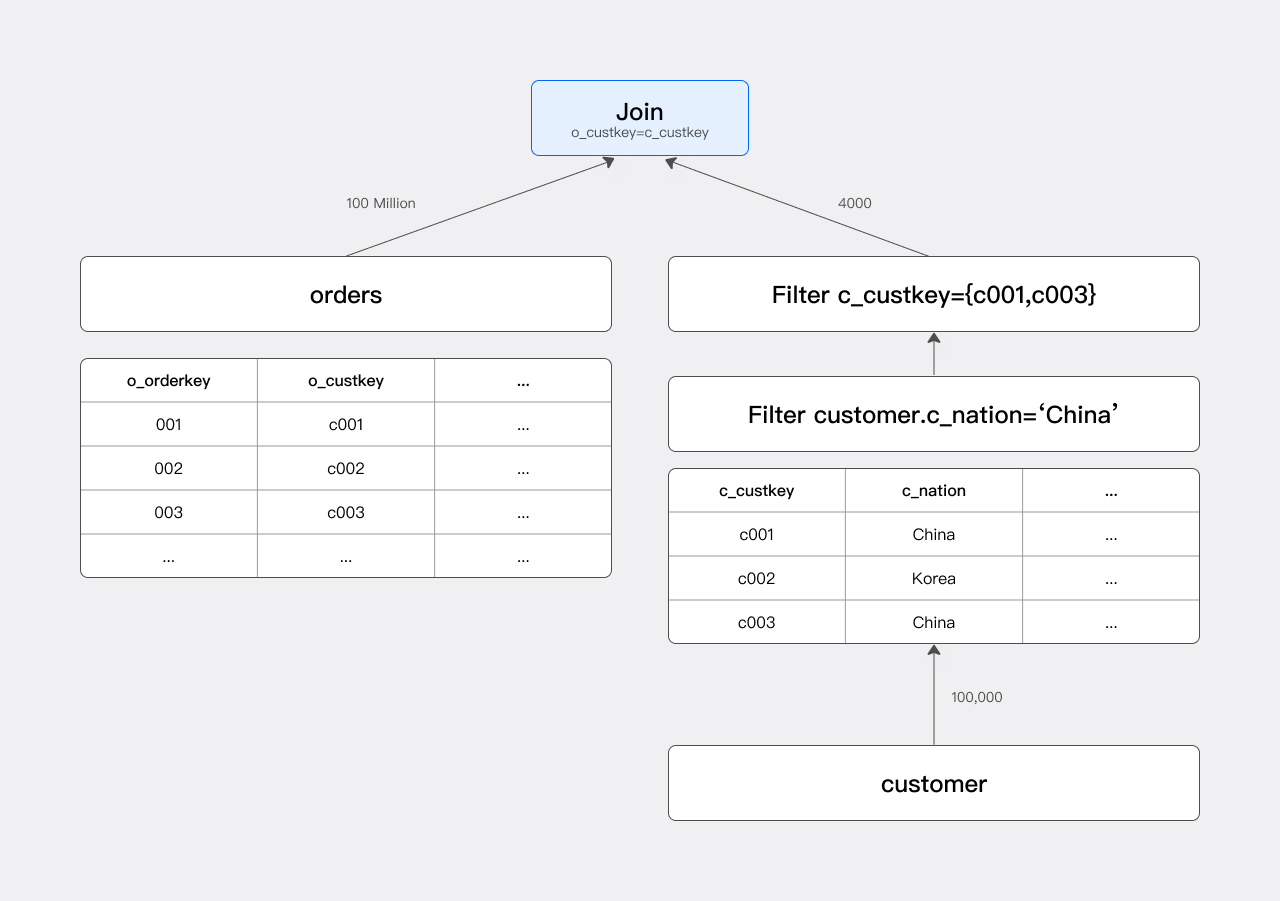
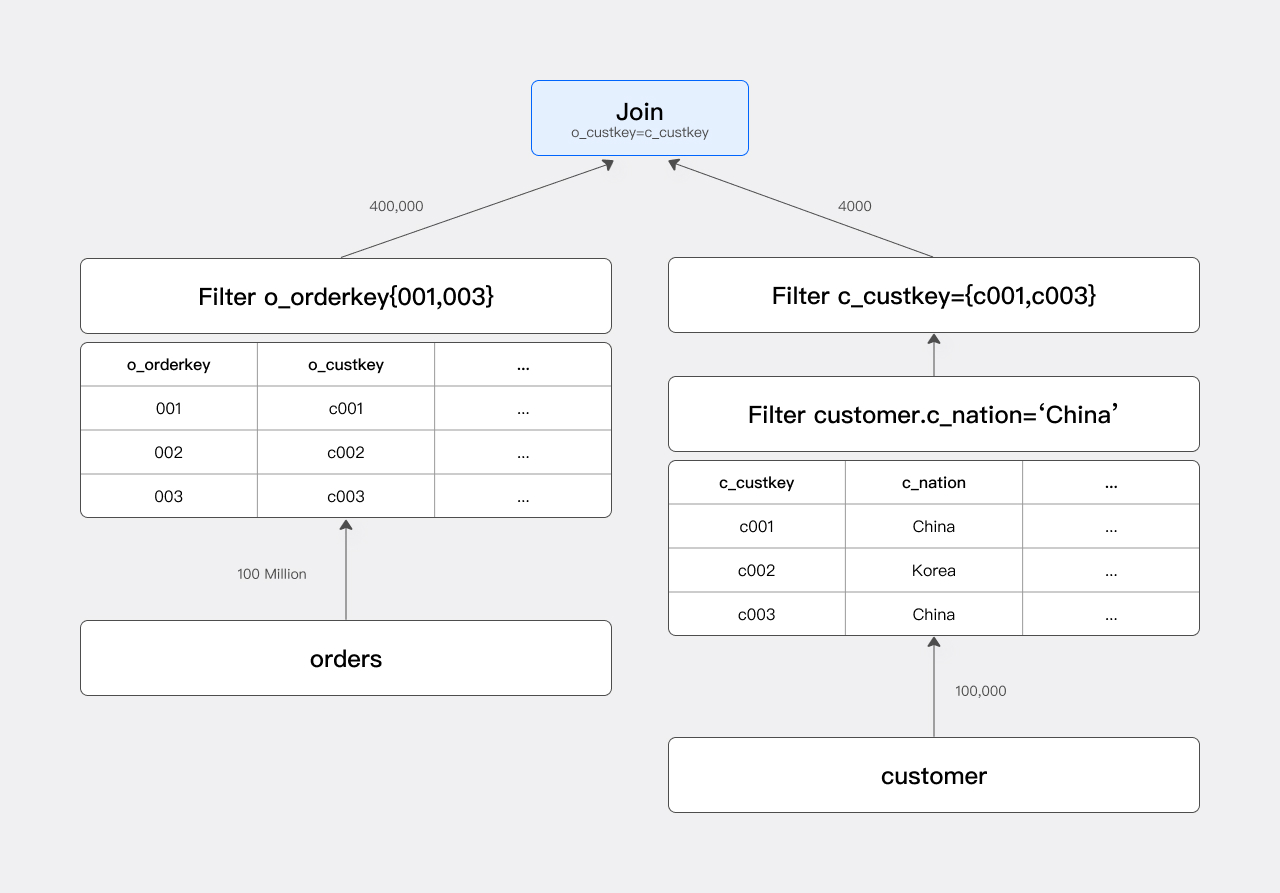
总结
在大数据领域我完全同意物理学中"more is different"的思想:当数据达到一定量级时,处理难度就会完全不一样。这时就需要对数据分布、引擎特性、底层实现等有深入的理解,才能对性能进行优化。但其实最好的优化就是减少数据量~

大数据性能调优
https://syntomic.cn/archives/performance-tuning