SQL Is All Your Need:SQL2API
对于数据开发人员来说,由于看数是企业中的一个普适需求,从CEO到普通员工都需要通过数据来做决策,故各种BI系统如Superset等技术栈成熟,在准备好数据后就能利用SQL配置好各种图表,发布相应报表。但如果需要建设定制化的数据产品,就必须提供对应的API服务能力,这就走出了数据开发的舒适区了,不仅要懂数据,还需要API设计、服务治理、SLA保障等后端工程能力。伴随着整体企业降本增效的旋律,如果能像做图表一样拖拉拽地利用SQL实现接口, 屏蔽掉后端工程的细节, 似乎可以大幅提高效率,本篇文章我们就来探讨一下SQL2API这样一种全新的后端开发模式。
案例分析
我们通过一个B站上的电影列表功能来看看,一个简单的数据接口需要具有哪些能力:
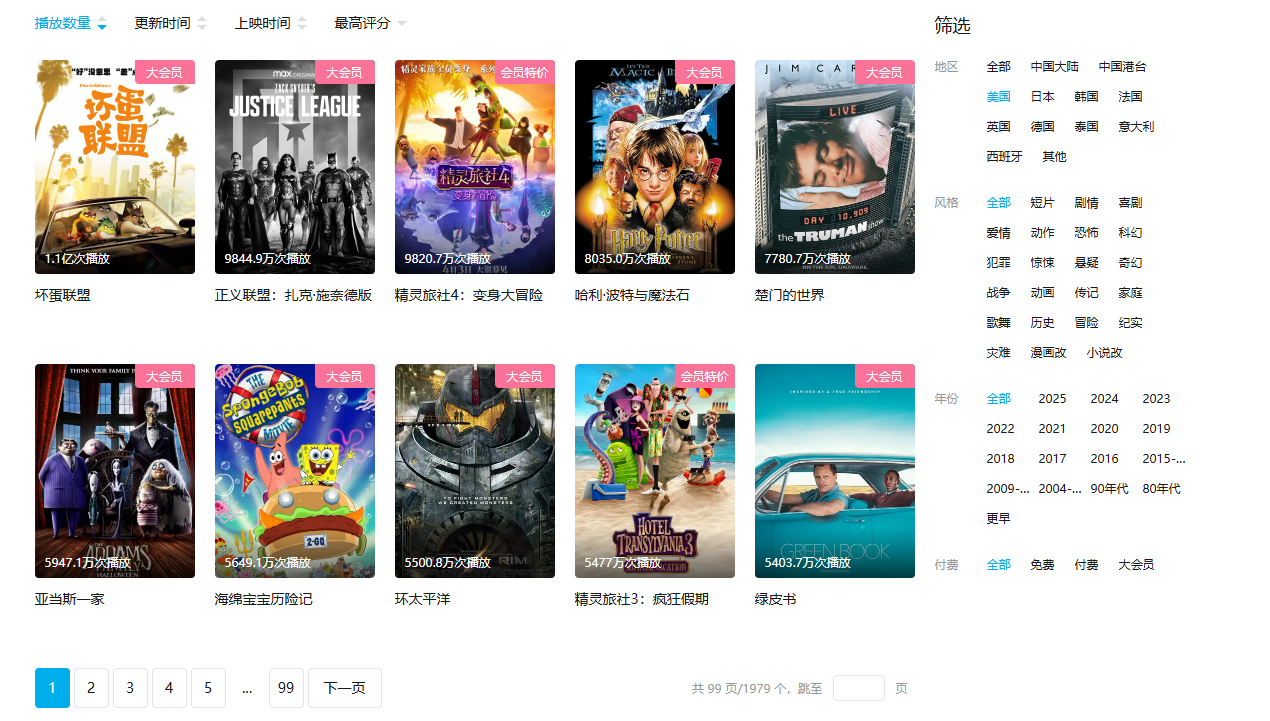
通过DevTools查看背后的接口实现:可以看出这个接口肯定不是数据开发人员开发的doge》
既然我们想用SQL开发接口,就需要把前端请求的参数转化为对应的SQL片段,并把SQL查询结果组装成JSON返回。
极简实现
假设现在有一张电影表:
CREATE TABLE movie (
title STRING COMMENT '电影名称',
cover STRING COMMENT '电影封面',
area STRING COMMENT '电影地区',
style STRING COMMENT '电影风格',
score DOUBLE COMMENT '电影评分',
play_cnt BIGINT COMMENT '电影播放次数'
)我们可以用SQL实现之前的查询逻辑,同时只需要定义变量就可以动态响应请求:
SELECT
title,
cover,
area,
AVG(score) AS score,
SUM(play_cnt) AS play_cnt
FROM
movie
WHERE
area = '美国'
GROUP BY
title,
cover,
area
ORDER BY play_cnt DESC
LIMIT 20 OFFSET 0; SELECT
title,
cover,
area,
AVG(score) AS score,
SUM(play_cnt) AS play_cnt
FROM
movie
WHERE
area = '{{$area}}'
GROUP BY
title,
cover,
area
ORDER BY {{$order}}
LIMIT {{$limit}} OFFSET {{$offset}};故而只要开发平台集成参数解析、SQL动态生成和结果封装等基础能力,只需要提供给我们相应的SQL开发界面,就能实现SQL2API的功能,比如阿里云的Dataphin。从此SQL又能开发接口,SQL Is All Your Need 诚不欺我~
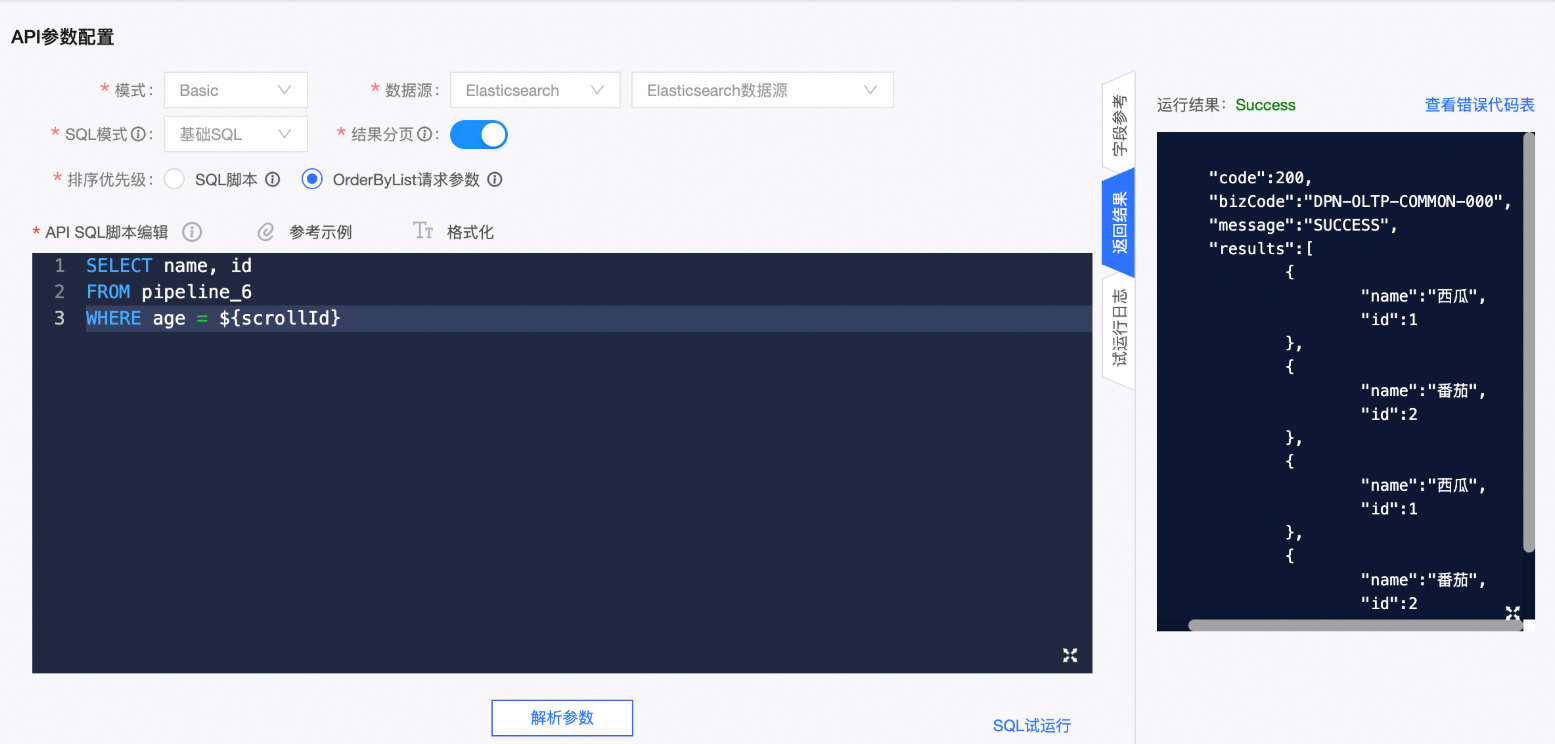
这样下游就可以按照统一的规范接入,比如之前的电影列表就可以按照如下的格式接入:
甚至我们可以把参数设置得更加灵活一些,比如增加group_by、extra等请求参数,直接依赖配置就能生成接口,连SQL都不用写了。但更复杂的业务逻辑就需要DAG编排才能实现了。
DAG编排
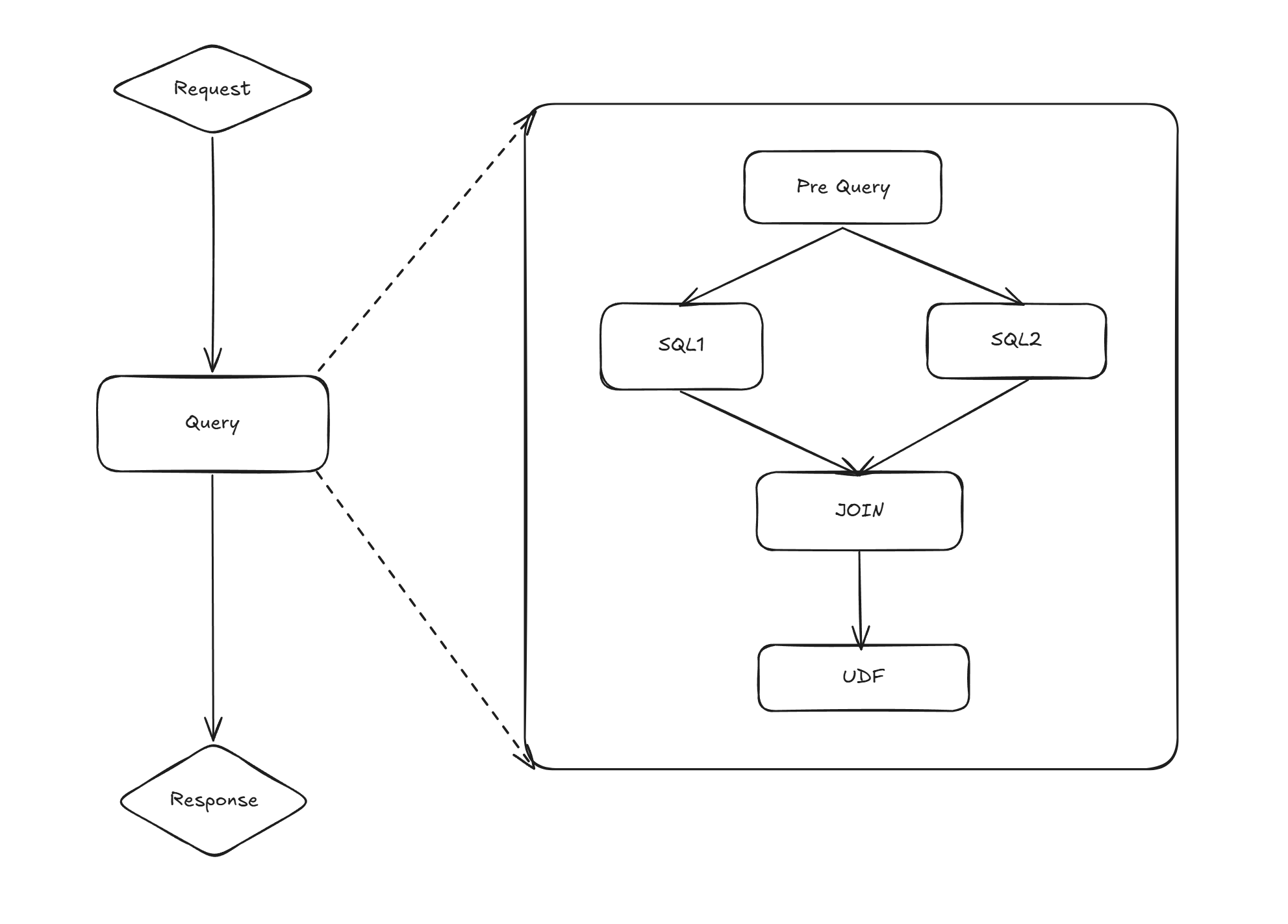
前置节点
如果我们需要在查询前获取相应的配置,比如我们查询电影数据范围,就可以先执行相应查询,将变量传入后续节点中。
SQL节点
模板语法:变量替换只能实现一些简单的逻辑,这时我们可以引入一些模板语法,实现遍历、函数等能力,比如上述例子可以用go template改写为:
SELECT
1 AS placeholder
{{range $i, $dim := $dimesinos}}
,{{$dim}}
{{end}}
{{range $i, $metirc := $metrics}}
,{{$metric}}
{{end}}
FROM
movie
WHERE
area = '{{$area}}'
GROUP BY
1
{{range $i, $dim := $dimesinos}}
,{{$dim}}
{{end}}
ORDER BY {{$order}}
LIMIT {{$limit}} OFFSET {{$offset}};关联节点
一般一些分析数据都存储在OLAP系统中,而一些配置信息可能存储在OLTP系统中,比如电影封面的大会员标记(badge)相关属性,这时候我们就可以从OLAP系统中查询电影的标记,然后在和OLTP中的标记属性关联,避免不同系统数据同步的麻烦。
UDF节点
SQL毕竟是声明式语言,有些逻辑还是用原生代码容易实现,比如电影的封面图需要根据ID去查询外部接口获取,这时候写一个外部接口调用UDF就容易实现了,(但这似乎和我们的slogan冲突了,其实写成SQL UDF也不是不可以》)
这样在提供各种不同能力的节点后,将这些节点组合编排起来,就可以实现一些复杂的业务逻辑。似乎这样能够有不错的效率提升,连数据都能把后端的活干了,全干工程师的未来已来?
总结
对于数据开发人员而言,简单的数据服务提供确实可以通过SQL2API实现,提升开发效率,但如果重心花在了DAG编排实现业务逻辑上,可能就得不偿失了。依我而言,数据和后端的职责还是需要划分清晰,数据开发负责 以数据查询为核心的、轻业务逻辑的“数据服务”接口,而后端开发负责 包含复杂业务逻辑、状态变更和事务的“业务服务”接口,这个度需要掌握好,两种都要做可能最终两种都做不好。