Fluss:重塑实时开发
大数据领域不时地出现一些名词,比如流批一体、湖仓一体、HSAP等,其实本质上就是在抹平界限,但笔者经历的实际落地场景并不多,核心原因就是在不牺牲原有功能的同时解决核心痛点。但最近结合Fluss的湖流一体出现,感觉它支持的特性可以重塑实时开发,整体感觉还不错,故本文就对Fluss的能力进行初步体验。
传统架构
下图是一个典型的大数据架构:首先通过数据集成任务将各种数据源接入到实时消息以及离线存储中,然后分实时链路和离线链路单独进行数仓分层建设,最终统一输出到OLAP引擎中提供在线服务。

这里很明显的一个问题就是实时和离线的一致性保证,这就是流批一体需要解决的问题,但本文专注于实时开发,我们来看看上面这条实时流面临哪些问题:
Kafka不支持更新:在处理更新流的时候,就需要将所有数据物化到Flink状态中,消耗大量资源。
Kafka查询能力弱:实时开发调试的时候,一般都是将Kafka数据在同步到OLAP中,增加额外的成本。
Kafka回溯数据难:实时数据只保留几天,在需要初始化回溯时需要单独开辟离线链路,增加系统复杂性。
Kafka 是为事件流设计的,而实时业务大多是分析场景——错配是这些痛点的共同根源。现在复杂逻辑都必须要单独在Flink中开发,导致整体实时开发成本过大。这时候我们需要一个面向分析场景的流式存储,看看第一个吃螃蟹的Fluss带来的改变吧:
更多的背景可以参考Fluss官方博客:Why Fluss,我们接下来看看具体如何使用Fluss。
更新:存储那缺失的能力
Fluss是面向实时分析(现在也加上了AI)设计的流存储, 它从底层将流和表融为一体,把数据看作是结构化的、支持更新的列式表:
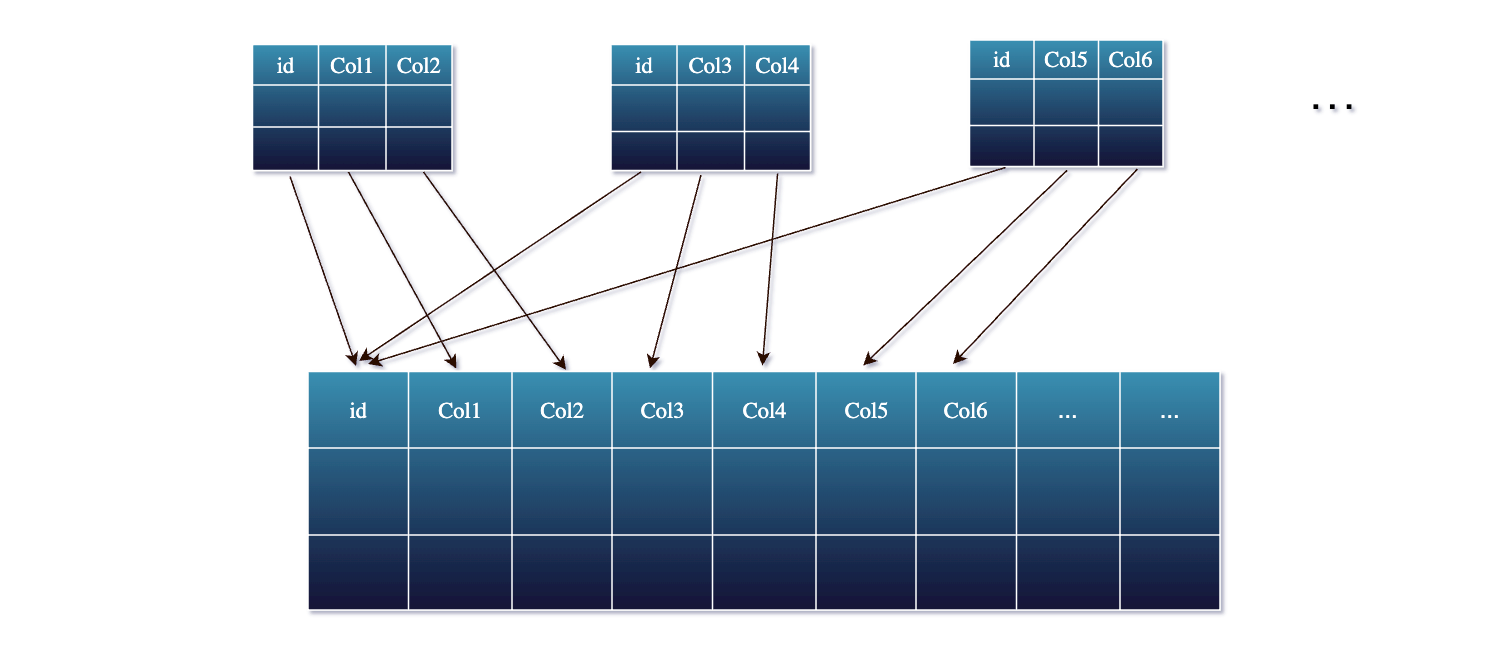
列式存储:基于 Apache Arrow实现,支持列裁剪和谓词下推。
主键更新: 支持主键表,写入时自动生成Changelog,省去大量的Flink状态开销。
数据湖集成:内置Tiering 服务,自动将温冷数据同步到数据湖中,支持合并查询。
交互式查询:内置KV索引,支持高效的主键Lookup查询,Debug方便。
例如:在传统的Kafka及Flink处理更新流中,需要在Flink任务中先进行Row number去重后,然后才能开发实际逻辑。但换成Fluss主键表后,它支持高效的Changelog生成,下游任务可以直接开发逻辑,同时支持维表关联,简化整体架构,提升数据复用度。

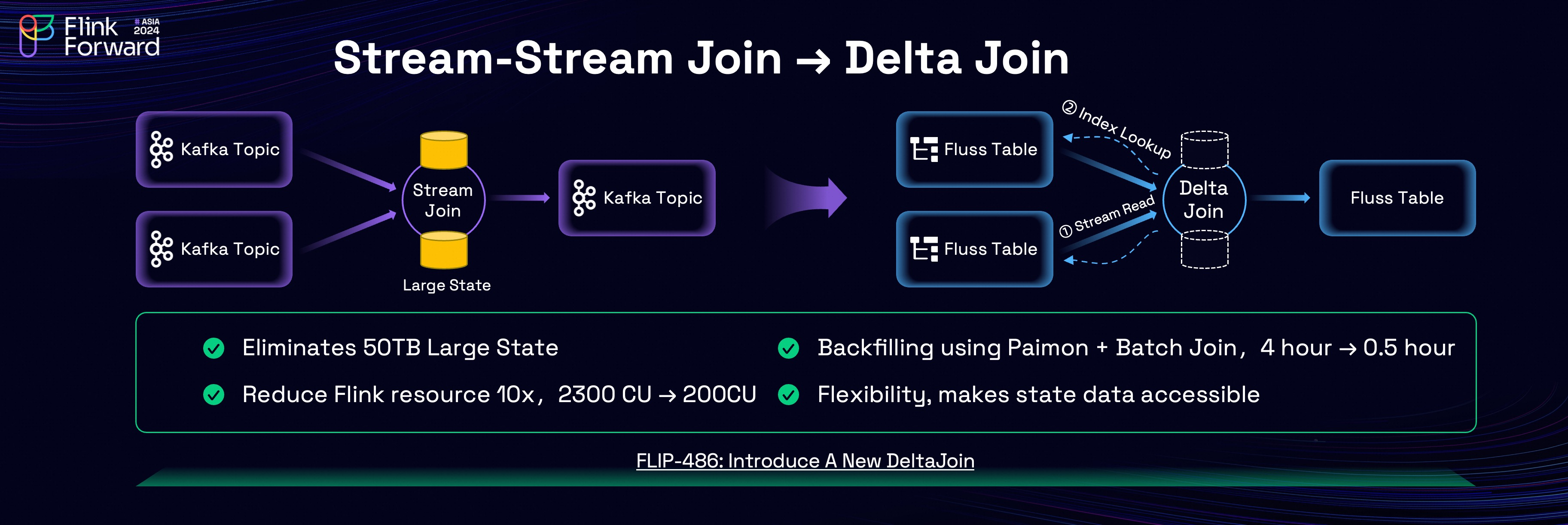
双流关联:终极BOSS
在 Flink 双流Regular Join 中,为了让两条流中相隔很久才到达的、具有相同 Key 的数据能够正确关联,Flink 必须在底层的 State 中永久且完整地保存两条流的历史数据,这就导致了状态爆炸和回撤流放大效应问题。让我们来看看Fluss是如何解决这个问题的。
主键:Partial Update
当关联键是两个流的主键时,可以直接利用Fluss的合并引擎,当一个流中部分更新到来时,fluss会查找改主键下的现有记录,更新提供的具体列,其他列保持不变,下游读到完整行的最新变更。
Partial Update示例代码
CREATE CATALOG fluss_catalog
WITH (
'type' = 'fluss',
'bootstrap.servers' = 'localhost:9123'
);
-- read from file for example
CREATE TEMPORARY TABLE IF NOT EXISTS fluss_catalog.fluss.fact_pk (
dim_a BIGINT,
metric BIGINT,
ts BIGINT,
PRIMARY KEY (dim_a) NOT ENFORCED
) WITH (
'connector' = 'filesystem',
'path' = 'file:///path/to/whatever',
'format' = 'json'
);
-- read from file for example
CREATE TEMPORARY TABLE IF NOT EXISTS fluss_catalog.fluss.dim (
dim_a BIGINT,
attr BIGINT,
ts BIGINT,
PRIMARY KEY (dim_a) NOT ENFORCED
) WITH (
'connector' = 'filesystem',
'path' = 'file:///path/to/whatever',
'format' = 'json'
);
CREATE TABLE IF NOT EXISTS fluss_catalog.fluss.fact_pk_dim_join (
dim_a BIGINT,
metric BIGINT,
fact_ts BIGINT,
attr BIGINT,
dim_ts BIGINT,
PRIMARY KEY (dim_a) NOT ENFORCED
) WITH (
'bucket.key' = 'dim_a'
);
-- * just insert, merged by fluss
INSERT INTO fluss_catalog.fluss.fact_pk_dim_join (dim_a, metric, fact_ts)
SELECT
dim_a,
metric,
ts AS fact_ts
FROM
fluss_catalog.fluss.fact_pk;
-- * just insert, merged by fluss
INSERT INTO fluss_catalog.fluss.fact_pk_dim_join (dim_a, attr, dim_ts)
SELECT
dim_a,
attr,
ts AS dim_ts
FROM
fluss_catalog.fluss.dim;外键:Delta Join
当关联键是外键时,基于索引进行高效双向Lookup来替换双流Join所维护的大状态,直接重用源表的数据。
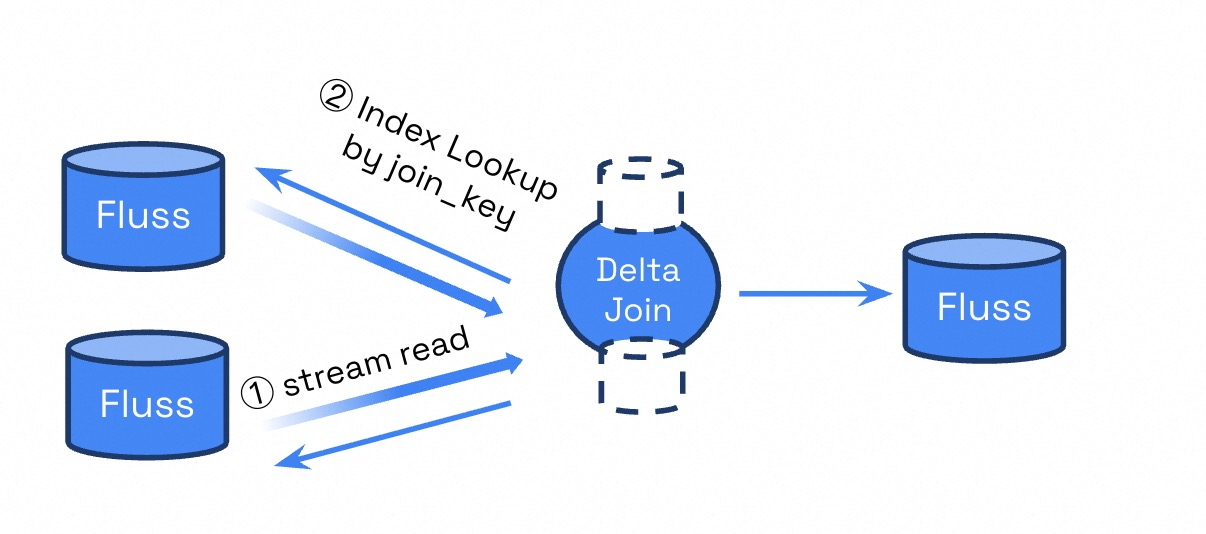
Delta Join示例代码
SET 'table.optimizer.delta-join.strategy' = 'FORCE';
CREATE CATALOG fluss_catalog
WITH (
'type' = 'fluss',
'bootstrap.servers' = 'localhost:9123'
);
CREATE TABLE IF NOT EXISTS fluss_catalog.fluss.fact_cdc (
dim_a BIGINT,
dim_b BIGINT,
metric BIGINT,
ts BIGINT,
PRIMARY KEY (dim_a, dim_b) NOT ENFORCED
) WITH (
'bucket.key' = 'dim_a',
-- Flink 2.1 only support append-only source
-- 'table.merge-engine' = 'first-row',
-- Flink 2.2 support cdc source
'table.delete.behavior' = 'ignore'
);
CREATE TABLE IF NOT EXISTS fluss_catalog.fluss.dim_cdc (
dim_a BIGINT,
attr BIGINT,
ts BIGINT,
PRIMARY KEY (dim_a) NOT ENFORCED
) WITH (
'bucket.key' = 'dim_a',
'table.delete.behavior' = 'ignore'
);
CREATE TABLE IF NOT EXISTS fluss_catalog.fluss.fact_dim_join (
dim_a BIGINT,
dim_b BIGINT,
metric BIGINT,
fact_ts BIGINT,
attr BIGINT,
dim_ts BIGINT,
PRIMARY KEY (dim_a, dim_b) NOT ENFORCED
) WITH (
'bucket.key' = 'dim_a'
);
INSERT INTO fluss_catalog.fluss.fact_dim_join
SELECT
fact_cdc.dim_a,
fact_cdc.dim_b,
fact_cdc.metric,
fact_cdc.ts AS fact_ts,
dim_cdc.attr,
dim_cdc.ts AS dim_ts
FROM
fluss_catalog.fluss.fact_cdc /*+ OPTIONS('scan.startup.mode' = 'earliest') */ fact_cdc
-- ! only support inner join
INNER JOIN
fluss_catalog.fluss.dim_cdc /*+ OPTIONS('scan.startup.mode' = 'earliest') */ dim_cdc
ON fact_cdc.dim_a = dim_cdc.dim_aDelta Join会输出重复数据,这是其做的一点妥协。我们可以用一点点的关系代数来解释:
可以看出来增量的关联关系分解式需要感知增量数据,也需要访问历史数据,只有少数存储系统支持快照,并至少会引入分钟级延迟。故将Delta将其变成了:
这样就只需要查找最新数据即可,但会增加一项 , 这就是数据重复的原因,详情可见:FLIP-486: Introduce A New DeltaJoin.
全局字典:Insert If Not Exists
在构建RoaringBitmap进行高效去重的时候,有两个关键的要求:id必须为整型且数据分布必须稠密。这个时候就可以利用Fluss的特性做一个全局字典进行id映射。

Insert If Not Exists代码示例
CREATE CATALOG fluss_catalog
WITH (
'type' = 'fluss',
'bootstrap.servers' = 'localhost:9123'
);
CREATE TEMPORARY TABLE IF NOT EXISTS fact (
dim_a BIGINT,
dim_b BIGINT,
metric BIGINT,
ts BIGINT,
ptime AS proctime(),
PRIMARY KEY (dim_a, dim_b) NOT ENFORCED
) WITH (
'connector' = 'filesystem',
'path' = 'file:///path/to/whatever',
'format' = 'json'
);
CREATE TABLE IF NOT EXISTS fluss_catalog.fluss.dim_mapping (
dim_b BIGINT,
uid_int32 BIGINT,
PRIMARY KEY (dim_b) NOT ENFORCED
) WITH (
'bucket.key' = 'dim_b',
'auto-increment.fields' = 'uid_int32'
);
SELECT
fact.dim_a,
fact.dim_b,
fact.metric,
fact.ts,
dim_mapping.uid_int32
FROM fact
LEFT JOIN fluss_catalog.fluss.dim_mapping /*+ OPTIONS('lookup.insert-if-not-exists' = 'true') */
FOR SYSTEM_TIME AS OF fact.ptime AS dim_mapping
ON fact.dim_b = dim_mapping.dim_b;聚合:Merge Aggregation
目前主流的聚合计算是在 Flink 计算引擎层执行,这种架构会带来显著的状态管理挑战,我们可以用Fluss的Aggregation Merge Engine,将聚合逻辑下推到存储引擎层,提升整体系统的可扩展性和性能。

为什么 Paimon 聚合引擎支持回撤,而 Fluss 不支持?
根源在可见性模型。Paimon 是快照事务可见,聚合在 compaction 阶段才发生,retract 可以作为 changelog 记录先落盘,再用 sum 等函数的逆元抵消;出错也能回滚到上一个 snapshot。
Fluss 是写入即可见,聚合在服务端同步应用,没有可丢弃的中间态。它靠 Undo Recovery 保证 exactly-once:checkpoint 记录 bucket offset,failover 时用 changelog 历史值硬覆盖回 checkpoint 时刻,再由 Flink replay 重算——这依赖"replay 是确定性 +I 流"。retract 打破了这个前提:上游 retract 序列在 replay 时不保证一致,且一旦同步应用就不可撤销。所以 Fluss 聚合表默认 'table.delete.behavior' = 'ignore'——这是当前模型下唯一安全的选择。
Paimon 用快照换来 retract 的可逆性,Fluss 用实时可见性换来写入路径的简单和低延迟——retract 恰好站在 Fluss 这条路径的反面。
湖流一体:Union Read
传统离线和实时数据是两条链路,在需要长周期计算以及实时回溯时,很难将两边数据对齐,但Fluss自带Tiering Service可以将实时数据按时同步到数据湖中,然后通过Union读取的方式,自动先读取Paimon数据湖中snapshot数据,然后切换到Fluss中实时数据,对业务暴露一张统一的逻辑表概念。

湖流一体代码示例
CREATE CATALOG fluss_catalog
WITH (
'type' = 'fluss',
'bootstrap.servers' = 'localhost:9123'
);
-- need start the tiering service flink job: https://fluss.apache.org/docs/maintenance/tiered-storage/lakehouse-storage/
CREATE TABLE IF NOT EXISTS fluss_catalog.fluss.fact_lake (
dim_a BIGINT,
dim_b BIGINT,
metric BIGINT,
ts BIGINT,
PRIMARY KEY (dim_a, dim_b) NOT ENFORCED
) WITH (
'bucket.key' = 'dim_a',
'table.datalake.enabled' = 'true',
'table.datalake.freshness' = '10s'
);
SELECT
dim_a,
SUM(metric) AS metric
FROM
-- * first read paimon snapshots, then read fluss
-- fluss_catalog.fluss.fact_lake
-- ! flink 2.2 cannot read by $lake, use flink 1.20 to read only paimon lake data.
-- fluss_catalog.fluss.fact_lake$lake
GROUP BY dim_a;总结
通过本文讨论的例子,可以看出计算和存储一起解决问题才是实时计算未来,现在Fluss整体生态还不太成熟,但设计理念确实目前实时开发的问题,也许不久的将来就可以换成下面的架构了,整体大数据体系越来越一体化了~

参考文献
https://help.aliyun.com/zh/flink/use-cases/processing-changelog-events-out-of-orderness-in-flink-sql
https://jack-vanlightly.com/blog/2025/9/2/understanding-apache-fluss
https://cwiki.apache.org/confluence/display/FLINK/FLIP-486%3A+Introduce+A+New+DeltaJoin
https://cwiki.apache.org/confluence/display/FLINK/FLIP-516%3A+Multi-Way+Join+Operator